Anhang E Redundant Array of Independent Disks (RAID)
Was verbirgt sich hinter RAID?
Die grundlegende Idee hinter RAID (Redundant Array of Independent Disks) besteht darin, mehrere kleine, preiswerte Festplatten zu einer Festplattengruppe zu kombinieren und dadurch eine höhere Leistung zu erreichen als mit einer großen und teuren Festplatte. Diese Festplattengruppe wird durch den Computer wie eine einzige logische Speichereinheit oder Festplatte angesprochen.
Bei dieser Methode werden Daten auf mehrere Festplatten unter Verwendungen von Techniken wie Disk Striping (RAID Level 0) und Disk Mirroring (RAID Level 1) verteilt, um Redundanz, geringere Latenzzeit und/oder größere Bandbreite zum Lesen und/oder Schreiben sowie die Möglichkeit zur Wiederherstellung der Datei nach dem Ausfall einer Festplatte zu gewinnen.
Das grundlegende Konzept von RAID ist, dass Daten auf jedes Laufwerk innerhalb der Laufwerkgruppe auf einheitliche Art und Weise verteilt werden können. Dazu müssen die Daten zuerst in "Blöcke" einheitlicher Größe aufgeteilt werden (oft 32 oder 64 KB groß, andere Größen sind möglich). Jeder Block wird dann abwechselnd auf jedes Laufwerk geschrieben. Wenn die Daten gelesen werden sollen, wird der Prozess umgekehrt. Dadurch entsteht der Eindruck, dass mehrere Laufwerke ein großes Laufwerk sind.
Wer sollte RAID verwenden?
Wer mit großen Datenmengen umgeht (z.B. ein typischer Administrator), kann von der RAID-Technologie profitieren. Zu den Hauptgründen für die Verwendung von RAID gehören:
Höhere Geschwindigkeit
Größere Speicherkapazität (und wirtschaftlicher)
Bessere Effizienz beim Wiederherstellen von Daten nach einem Plattenausfall
RAID: Hardware- oder Software-Lösung
Es gibt zwei mögliche Ansätze für RAID: Hardware-RAID und Software-RAID.
Hardware-RAID
Das Hardware-basierte System verwaltet das RAID-Teilsystem unabhängig vom Rechner und stellt für den Rechner nur eine einzige Festplatte pro RAID-Array dar.
Ein Beispiel für ein Hardware-RAID-Gerät wäre eine Einheit, die an einen SCSI-Controller angeschlossen ist und deren RAID-Array wie ein einziges SCSI-Laufwerk angesprochen wird. Ein externes RAID-System verlagert alle RAID-Steuerungsprozesse in einen Controller, der sich im externen Festplattenteilsystem befindet. Das ganze Teilsystem wird über einen normalen SCSI-Controller an den Rechner angeschlossen und erscheint für diesen als "ganz normale" Festplatte.
RAID-Controller werden auch in Form von Karten angeboten, die für das Betriebssystem wie ein SCSI-Controller agieren, jedoch die gesamte Kommunikation mit den RAID-Laufwerken übernehmen. In diesen Fällen werden die Laufwerke genauso an den RAID-Controller angeschlossen wie an einen SCSI-Controller. Danach werden sie in die Konfiguration des RAID-Controllers eingetragen, so dass das Betriebssystem den Unterschied zu herkömmlichen Laufwerken nicht mehr erkennt.
Software-RAID
Beim Software-RAID sind die verschiedenen RAID-Levels im Kernel-Disk-(Blockgeräte-) Code implementiert. Dieser Ansatz ist die preiswerteste Lösung: Es werden keine teuren Festplattencontroller oder Hot-Swap-Chassis benötigt [1], und Software-RAID funktioniert mit billigeren IDE-Festplatten ebenso wie mit SCSI-Festplatten. Mit den heutigen schnellen CPUs übertrifft die Leistung von Software-RAID-Systemen sogar die von Hardware-RAID-Systemen.
Der MD-Treiber im Linux-Kernel ist ein Beispiel für eine RAID-Lösung, die vollkommen hardwareunabhängig ist. Die Leistung eines Software-basierten Arrays ist sehr stark abhängig von Leistung und Auslastung der Server-CPU.
Einige Funktionsmerkmale von RAID
Für alle, die sich für Software-RAID interessieren, geben wir hier eine kurze Liste einiger der Funktionsmerkmale an:
Wiederherstellungs-Prozess mit Threads
Vollständig Kernel-basierte Konfiguration
Portabilität von Arrays zwischen Linux-Rechnern ohne Reorganisation
Reorganisation von Arrays erfolgt im Hintergrund unter Verwendung ungenutzter Systemressourcen
Unterstützung von Hotswap-fähigen Laufwerken
Automatische CPU-Erkennung, um bestimmte CPU-Optimierungen voll auszunutzen
Levels und lineare Unterstützung
RAID bietet außerdem die Level 0, 1, 4, 5 und lineare Unterstützung. Diese RAID-Typen funktionieren folgendermaßen:
Level 0 - RAID Level 0, oftmals als "Striping" bezeichnet, ist eine leistungsorientierte Datenzuordnungstechnik. Das heißt, die in das Array zu schreibenden Daten werden zerlegt und auf die einzelnen Festplatten des Arrays verteilt. Dies ermöglicht eine hohe E/A-Leistung bei geringen zusätzlichen Kosten, bietet jedoch keine Redundanz. Die Speicherkapazität des Arrays entspricht der Gesamtkapazität aller Festplatten des Arrays.
Level 1 - RAID Level 1, oder "Mirroring", wird bereits länger als alle anderen RAID-Formen eingesetzt. Level 1 gewährleistet Redundanz, indem die gleichen Daten auf jede einzelne Festplatte des Arrays geschrieben werden, so dass auf jeder Festplatte eine "gespiegelte" Kopie vorliegt. Diese Vorgehensweise bleibt wegen ihrer Einfachheit und hohen Datenverfügbarkeit weiterhin populär. Sie funktioniert mit zwei oder mehreren Festplatten, die für hohe Datenübertragungsgeschwindigkeiten mit parallelem Zugriff lesen können, aber normalerweise für hohe E/A-Transaktionsraten unabhängig voneinander arbeiten. Level 1 bietet sehr gute Datensicherheit und verbessert die Leistung für leseintensive Anwendungen, jedoch bei relativ hohen Kosten. [2] Wenn Sie identische Festplattenlaufwerke verwenden, dann entspricht die Kapazität des Arrays der Kapazität einer einzelnen Festplatte im Array.
Level 4 - Level 4 verwendet Prüfbits [3] die zum Datenschutz auf einer einzigen Festplatte konzentriert sind. Dieses Verfahren eignet sich eher für E/A-Vorgänge als für die Übertragung großer Dateien. Da die eigens für Prüfbits bestimmte Festplatte einen Engpass darstellt, wird Level 4 selten ohne unterstützende Techniken wie Write Back Caching verwendet. Obwohl RAID Level 4 für einige RAID-Partitionsvarianten verwendet werden kann, ist es für Red Hat Linux RAID-Installationen nicht zugelassen. [4] Die Kapazität des Arrays entspricht der Kapazität der Festplatten im Array minus der Kapazität einer Festplatte, falls Sie identische Festplattenlaufwerke verwenden.
Level 5 - Der am weitesten verbreitete RAID-Typ. Durch Verteilen der Prüfbits auf einige oder alle Array-Laufwerke wird der Schreibengpass von Level 4 eliminiert. Den einzigen Engpass bildet jetzt die Prüfsummenbildung, was jedoch mit modernen CPUs und Software-RAID kein nennenswertes Problem ist. Wie bei Level 4 ist das Ergebnis ein asymmetrisches Leistungsverhalten, wobei Lesevorgänge erheblich schneller ablaufen als Schreibvorgänge. Um diese Asymmetrie zu verringern, wird Level 5 häufig zusammen mit Write-back verwendet. Die Kapazität des Arrays entspricht der Kapazität der Festplatten im Array minus der Kapazität einer Festplatte, falls Sie identische Festplattenlaufwerke verwenden.
Lineares RAID - Lineares RAID ist die einfache Zusammenschaltung von Festplatten, um so zu einer größeren virtuellen Festplatte zu gelangen. Beim linearen RAID werden die Blöcke jeweils auf die nächste Festplatte geschrieben, wenn die vorhergehende Festplatte voll ist. Diese Gruppierung bringt keinen Leistungsvorteil, da es unwahrscheinlich ist, dass E/A-Operationen zwischen verschiedenen Festplatten aufgeteilt werden. Lineares RAID bietet auch keine Redundanz und reduziert sogar die Zuverlässigkeit - wenn eine der Festplatten ausfällt, funktioniert das gesamte Array nicht mehr. Die Kapazität berechnet sich aus der Summe der Kapazitäten aller Festplatten.
Erstellen von RAID-Partitionen
RAID ist sowohl bei Verwendung der grafischen Oberfläche als auch im Kickstart-Installationsmodus verfügbar. Ihre RAID-Konfiguration können Sie mit fdisk oder Disk Druid erstellen. Diese Anleitung konzentriert sich jedoch hauptsächlich auf die Verwendung von Disk Druid für diese Aufgabe.
Bevor Sie ein RAID-Gerät erstellen können, müssen zuerst RAID-Partitionen erstellt werden. Gehen Sie dabei nach der folgenden Schritt-für-Schritt-Anweisung vor.
 | Tipp: Verwendung von fdisk |
|---|---|
Wenn Sie fdisk zum Erstellen einer RAID-Partition verwenden, ist Folgendes zu beachten: Sie müssen statt einer Partition vom Typ 83 (= Linux Native) eine Partition vom Typ fd (Linux RAID) erstellen. Die beste Leistung erzielen Sie außerdem, wenn die Partitionen innerhalb eines festgelegten RAID-Arrays auf den Laufwerken identische Zylinder umfassen. |
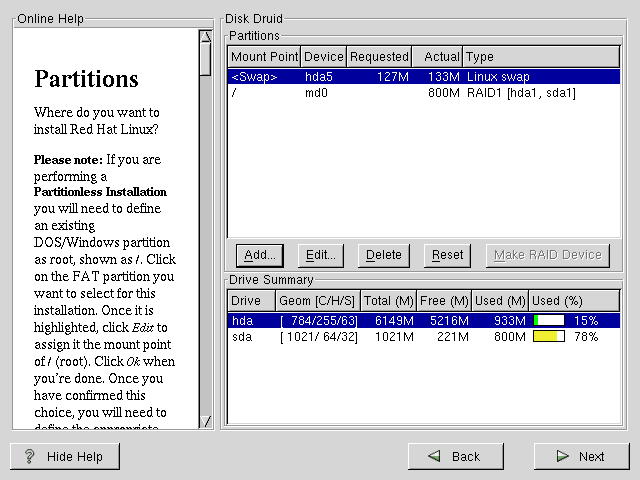
Erstellen Sie eine Partition. In Disk Druid müssen Sie Hinzufügen wählen, um eine neue Partition zu erstellen (siehe Abbildung E-1).
Sie können dabei noch keinen Mount-Point eingeben. (Das können Sie erst, wenn Sie Ihr RAID-Gerät erstellt haben.)
Geben Sie die Größe der Partition ein.
Aktivieren Sie das Kontrollkästchen An Kapazität der Festplatte anpassen, wenn Sie die Partition so anpassen wollen, dass sie die gesamte Festplatte einnimmt. Ihre Größe ist variabel und hängt davon ab, wie Sie die anderen Partitionen festlegen. Wenn Sie mehr als eine anpassbare Partition erstellen, dann werden die verschiedenen Partitionen um den verfügbaren freien Festplattenplatz konkurrieren.
Geben Sie RAID als Partitionstyp an.
Wählen Sie schließlich unter Verfügbare Laufwerke das RAID-Laufwerk aus. Wenn Sie über mehrere Laufwerke verfügen, werden hier alle Laufwerke aktiviert. Sie müssen diejenigen Laufwerke deaktivieren, auf denen kein RAID-Array erstellt werden soll.
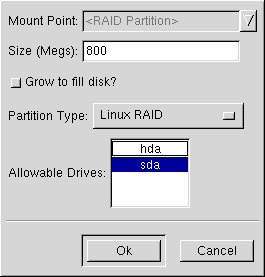
Fahren Sie auf diese Weise fort, und erstellen Sie so viele Partitionen, wie für das RAID-Array benötigt werden.
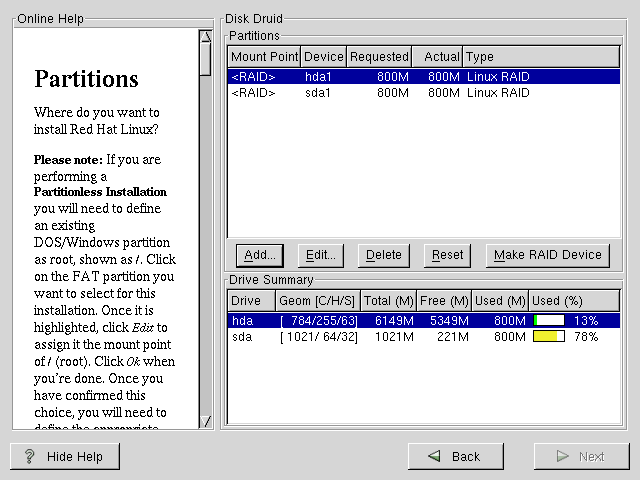
Wenn Sie alle RAID-Partitionen erstellt haben, wählen Sie die Schaltfläche RAID-Gerät erstellen im Hauptpartitionierungsbildschirm von Disk Druid (siehe Abbildung E-2).
Dann erscheint Abbildung E-3. Hier können Sie ein RAID-Gerät erstellen.
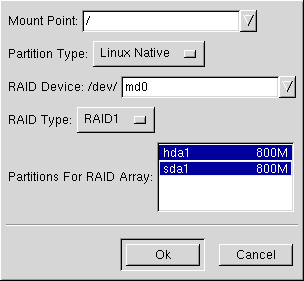
Geben Sie zuerst einen Mount-Point an.
Überprüfen Sie dann, ob der Partitionstyp auf Linux Native eingestellt ist (Standardvorgabe).
Wählen Sie Ihr RAID-Gerät aus. Wählen Sie für das erste Gerät md0, für das zweite Gerät md1 usw., es sei denn es liegt ein wichtiger Grund vor, andere Bezeichnungen für die Geräte auszuwählen. Für RAID-Geräte können die Bezeichnungen md0 bis md7 und jede nur einmal verwendet werden.
Wählen Sie den RAID-Typ aus. Sie können zwischen RAID 0, RAID 1 und RAID 5 wählen.

Bitte beachten Wenn Sie eine RAID-Partition von /boot erstellen, müssen Sie RAID Level 1 auswählen. Zudem muss eines der ersten beiden Laufwerke (IDE als erstes, SCSI als zweites) verwendet werden. Wenn Sie keine RAID-Partition von /boot, sondern von / erstellen, müssen Sie ebenfalls RAID Level 1 auswählen. Auch in diesem Fall muss eines der beiden ersten Laufwerke (IDE als erstes, SCSI als zweites) verwendet werden.
Wählen Sie schließlich die Partitionen aus, die zum RAID-Array gehören sollen (siehe Abbildung E-4), und klicken Sie auf Weiter.
Ab hier können Sie mit dem Installationsprozess fortfahren. Weitere Informationen finden Sie im Offiziellen Red Hat Linux Installationshandbuch.