In conjunction
with computers, the term conferencing
is often used in two different ways. One refers to bulletin boards and mail
list asynchronous exchanges of
messages between multiple users; secondly, one may refer to synchronous or so-called real-time conferencing, including
audio/video communication and shared tools such as whiteboards and other
applications. This document is about
the architecture for this latter application, multimedia conferencing in an Internet
environment. There are other
infrastructures for teleconferencing in the world: POTS (Plain Old Telephone
System) networks often provide voice conferencing and phone-bridges, while with
ISDN, H.320 [h320] can be used for small, strictly organised video-telephony
conferencing. This latter infrastructure will be called ITU Conferencing in this report.
The use of the
term architecture in the title of this document should be understood neither as
meaning plans for building specific software nor an inflexible environment in
which conferencing must operate; it is a description of the context in which
the project is working and the requirements for individual elements of that
conferencing environment. It also includes the type of components which the
MECCANO partners are committed to provide. Moreover, this document does not
intend to give a complete bibliography of multimedia conferencing, or even
Mbone multicast conferencing tools. It references mainly those used within the
MECCANO project. We use directly many tools deriving from the earlier
activities of the Lawrence Berkeley Laboratories (LBL) [lbl] and the European
projects MICE [mice] and MERCI [merci]. We are fully aware of the later work of
MASH [mash], MATES [mates] and MARRATECH [marra]. The first is insufficiently
modular for us to include parts; the commercial nature of the latter two has
made it difficult to integrate them with parts of our system, in order to
provide the extension we need for security, loss-resistance and multiple
platforms.
Most of this
Deliverable is about the architecture of multicast conferencing and data
delivery as being developed in the Internet Engineering Task Force [ietf]. The Mbone is used to describe that portion
of the Internet, which supports multicast data distribution; while this is currently
being used mainly for conferencing and the distribution of multimedia
broadcasting, there are many other uses of the technology. For the sake of
notation only, this form of conferencing will be called Mbone Conferencing. There used to be a clean divide between this
conferencing architecture and that being pursued in the ITU as exemplified by
H.320 for ISDN conferencing; the former used the Internet, the latter the ISDN
or POTS. Recently the distinction has become somewhat blurred, because at the
lower transport levels the ITU has adopted the same procedures as IETF [h323];
this means that ITU-style conferences can also use the Internet. There are
still some differences, but there is also clear overlap. The architectural
environment of the ITU mechanisms do not scale as well, but for small, tightly
controlled, conferences they are a quite viable alternative.
Since most of the
MECCANO project is about the use of Mbone conferencing, more detail will be
given of this technology. However, one part of the project is concerned with
the provision of facilities to allow ITU-conferencing workstations to join
Mbone conferences and to allow Mbone-conferencing workstations to join ITU
conferences. For this reason enough detail will be provided to define the
requirements for the gateways needed. In addition, we will attempt to indicate
over what range of parameters we consider it desirable to use the ITU
conferencing concepts - and even where some of those concepts could be added to
Mbone conferencing.
Sections 2, 3, 4
and 6 are based on “The Internet Multimedia Conferencing Architecture”, an
overview of Mbone conferencing being prepared both as a paper and a submission
to the MMUSIC group of the IETF [han99-3]. There are some differences between
the current draft of that paper and the relevant sections of this document.
These reflect that the purpose of this Deliverable is to define the MECCANO
architecture. This is closely aligned to the activity of the MMUSIC group, but
there are differences of emphasis. Moreover, we address issues that are not
addressed in that paper, and often are not even appropriate to the IETF. There
are two reasons for referring to that here. First we wish to acknowledge our
substantial debt to the authors of [han99-3]; secondly, we do not imply that
all the statements here have the approval of the authors of [han99-3].
The Mbone
architecture is only one of the architectures being considered in the MECCANO
project. Another is the ITU one, exemplified by H.323. This follows a much more
conventional ITU approach, which is sender driven. An earlier complete
independence of protocol structures in the H.320 family has become more similar
in the H.323 version because both use the same underlying transport protocols.
The methods of control and initiation are very different, but it is meaningful
to consider H.323 workstations joining Mbone conferences and vice-versa -
without undue processing on the media streams themselves during the running
conferences. Section 7 gives the salient properties of the ITU architecture.
There are many
other areas being explored in the project, most of which have architectural
considerations. In Section 8 we consider the various gateways being considered;
some of these are between the Mbone and the ITU worlds; others are between
different types of technology. Others are concerned with overcoming the
justified fears that many organisations have to allowing multicast into their
organisations. In Section 9 we consider the mechanisms which are required to
provide privacy in conferences, and to allow authentication both of
participants and the activities of conference organisers.
Other sections
deal with the architectural implications of various tools and components. Thus
in Section 3 we consider aspects of supporting various network types, in
Sections 4 and 5 we consider the architectures of the Mbone tools and in
Section 10 those of the recording and replay media servers. Finally, some
conclusions are drawn in Section 11.
The architecture
that has evolved in the Internet is general as well as being scalable to very
large groups; it permits the open introduction of new media and new
applications as they are devised. As the simplest case, it also allows two
persons to communicate via audio only; i.e. it encompasses IP telephony.
The determining
factors of conferencing architecture are communication between (possibly large)
groups of humans and real-time delivery of information. In the Internet, this is supported at a
number of levels. The remainder of this
section provides an overview of this support, and the rest of the document
describes each aspect in more detail.
In a conference,
information must be distributed to all the conference participants. Early conferencing systems used a fan-out of
data streams, e.g., one connection between each pair of participants, which
means that the same information must cross some networks more than once. The
Internet architecture uses the more efficient approach of multicasting the
information to all participants (cf. Section 3.1).
Multimedia
conferences require real-time delivery of at least the audio and video
information streams used in the conference.
In an ISDN context, fixed rate circuits are allocated for this purpose -
whether their bandwidth is required at any particular instance or not. On the
other hand, the traditional Internet service model (best effort) cannot make the necessary Quality of Service (QoS)
available in congested networks. New
service models are being defined in the Internet together with protocols to
reserve capacity or prioritise traffic in a more flexible way than that
available with circuit switching (cf. Section 3.2).
In a datagram
network, multimedia information must be transmitted in packets, some of which
may be delayed more than others. In order that audio and video streams be
played out at the recipient in the correct timing, information must be
transmitted that allows the recipient to reconstitute the timing. A transport
protocol with the specific functions needed for this has been defined (cf.
Section 4.1). The Internet is a very
heterogeneous world. Techniques exist to exploit this, and to deliver
appropriate quality to different participants in the same conference according to
their capabilities.
The humans
participating in a conference generally need to have a specific idea of the
context in which the conference is happening, which can be formalised as a
conference policy. Some conferences are essentially crowds gathered around an
attraction, while others have very formal guidelines on who may take part
(listen in) and who may speak at which point.
In any case, initially the participants must find each other, i.e.
establish communication relationships (conference set-up, Section 6.2).
During the conference, some conference control information is exchanged
to implement a conference policy or at least to inform the participants of who
is present.
In addition,
security measures may be required to actually enforce the conference policy,
e.g. to control who is listening and to authenticate contributions as
purporting to originate from a specific person. In the Internet, there is little tendency to rely on the
traditional security of distribution
offered e.g. by the phone system.
Instead, cryptographic methods are used for encryption and
authentication, which need to be supported by additional conference set-up and
control mechanisms (See Section 9).

Figure 1 Internet
multimedia conferencing protocol stacks
Most of the
protocol stacks for Internet multimedia conferencing are shown in Fig. 1. Most of the protocols are not deeply
layered, unlike many protocol stacks, but rather are used alongside each other
to produce a complete conference. For secure conferencing, there may be
additional protocols for group management. This question is addressed in
Section 9.
IP multicast
provides efficient many-to-many data distribution in an Internet
environment. It is easy to view IP
multicast as simply an optimisation for data distribution; indeed this is the
case, but IP multicast can also result in a different way of thinking about
application design. To see why this
might be the case, examine the IP multicast service model, as described by Jacobson
[jacobson95]:
·
Senders just send to the group
·
Receivers express an interest in receiving data sent to the group
·
Routers conspire to deliver data from senders to receivers
With IP
multicast, the group is indirectly identified by a single IP class-D multicast
address.
Several things
are important about this service model from an architectural point of
view. Receivers do not need to know who
or where the senders are to receive traffic from them. Senders never need to know who the receivers
are. Neither senders nor receivers need
care about the network topology as the network optimises delivery.
The level of
indirection introduced by the IP class D address denominating the group solves
the distributed systems binding problem, by pushing this task down into
routing. Given a multicast address (and UDP port), a host can send a message to
the members of a group without needing to discover who they are. Similarly receivers can tune in to multicast data sources without needing to bother the
data source itself with any form of request.
IP multicast is a
natural solution for multi-party conferencing because of the efficiency of the
data distribution trees, with data being replicated in the network at
appropriate points rather than in end-systems.
It also avoids the need to configure special-purpose servers to support
the session; such servers require support, cause traffic concentration and can
be a bottleneck. For larger
broadcast-style sessions, it is essential that data-replication is carried out
in a way that requires only that per-receiver network-state is local to each
receiver, and that data-replication occurs within the network. Attempting to configure a tree of
application-specific replication servers for such broadcasts rapidly becomes a multicast routing problem; thus native
multicast support is a more appropriate solution.
There are a
number of IETF documents outlining the requirements of Hosts and multicast
routing. The most important, defining the Host extensions for IP multicast, are
[ipm]. There are many mechanisms, which have been proposed for multicast
routing; some of these are described in [dvmrp], [pimsm], [pimdm] and [bal98].
It is beyond the scope of this Deliverable to discuss the differences and
advantages of the different proposals.
There is an
important question on how an application chooses which multicast address to
use. In the absence of any other information, we can bootstrap a multicast
application by using well-known multicast addresses. Routing (unicast and multicast) and group membership protocols
[deer88-1] can do just that. However,
this is not the best way of managing applications of which there is more than
one instance at any one time.
For these, we
need a mechanism for allocating group addresses dynamically, and a directory
service which can hold these allocations together with some key (session
information for example - see later), so that users can look up the address
associated with the application. The
address allocation and directory functions should be distributed to scale well.
Multicast address
allocation is currently an active area of research. For many years multicast
address allocation has been performed using multicast session directories (cf.
Section 6.2), but as the users and uses of IP multicast increase, it is
becoming clear that a more hierarchical approach is required.
An architecture
[han99-2] is currently being developed based around a well-defined API that an
application can use to request an address.
The host then requests an address from a local address allocation
server, which in turn chooses and reserves an unallocated address from a range
dynamically allocated to the domain. By
allocating addresses in a hierarchical and topologically sensitive fashion, the
address itself can be used in a hierarchical multicast routing protocol
currently being developed (BGMP, [thal98]) that will help multicast routing
scale more gracefully that current schemes.
A number of
specific documents giving methods for address allocation are given in [estr99]
and [phil98]. It is relevant also to consider the extensions required to
resource discovery protocols using multicast [patel99].
Traditionally the
Internet has provided so-called best-effort
delivery of datagram traffic from senders to receivers. No guarantees are made regarding when or if
a datagram will be delivered to a receiver, however, datagrams are normally
only dropped when a router exceeds a queue size limit due to congestion. The best-effort Internet service model does
not assume FIFO queuing, although many routers have implemented this.
With best-effort
service, if a link is not congested, queues will not build at routers,
datagrams will not be discarded in routers, and delays will consist of
serialisation delays at each hop plus propagation delays. With sufficiently fast link speeds,
serialisation delays are insignificant compared to propagation delays. For slow
links, a set of mechanisms has been defined that helps minimise serialisation
and link access delay is low.
If a link is
congested, with best-effort service, queuing delays will start to influence
end-to-end delays, and packets will start to be lost as queue size limits are
exceeded. High quality real-time
multimedia traffic does not cope well with packet loss levels of more than a
few percent unless steps are taken to mitigate its effects. One such step is
the use of redundant encoding [redenc] to raise the level at which loss becomes
a problem. In the last few years a
significant amount of work has also gone into providing non-best-effort
services that would provide a better assurance that an acceptable quality
conference will be possible.
Real-time
Internet traffic is defined as that carried by datagrams that are delay
sensitive. It could be argued that all
datagrams are delay sensitive to some extent, but for these purposes we refer
only to datagrams where exceeding an end-to-end delay bound of a few hundred
milliseconds renders the datagrams useless for the purpose they were intended. For the purposes of this definition, TCP
traffic is normally not considered to be real-time traffic, although there may
be exceptions to this rule.
On congested
links, best-effort service queuing delays will adversely affect real-time
traffic. This does not mean that
best-effort service cannot support real-time traffic - merely that congested
best-effort links seriously degrade the service provided. For such congested links, a
better-than-best-effort service is desirable. To achieve this, the service
model of the routers can be modified. FIFO queuing can be replaced by packet
forwarding strategies that discriminate different flows of traffic. The idea
of a flow is very general. A flow might
consist of all marketing site web traffic,
or all fileserver traffic to and from
teller machines. On the other hand,
a flow might consist of a particular sequence of packets from an application in
a particular machine to a peer application in another particular machine set up
on request, or it might consist of all packets marked with a particular
Type-of-Service bit.
There is really
a spectrum of possibilities for non-best-effort service something like that
shown in Fig. 2.

Figure 2
Spectrum of Internet service types
This spectrum is
intended to illustrate that between best-effort and hard per-flow guarantees
lie many possibilities for non-best-effort service. These include having hard
guarantees based on an aggregate reservation, assurances that traffic marked
with a particular type-of-service bit will not be dropped so long as it remains
in profile, and simpler prioritisation-based services.
Towards the right
hand side of the spectrum, flows are typically identifiable in the Internet by
the tuple: source machine, destination
machine, source port, destination port, protocol, any of which could be
“ANY” (wildcarded).
In the multicast
case, the destination is the group, and can be used to provide efficient
aggregation.
Flow
identification is called classification; a class (which can contain one or more
flows) has an associated service model applied. This can default to best effort.
Through network
management, we can imagine establishing classes of long-lived flows. For
example, Enterprise networks (Intranets)
often enforce traffic policies that distinguish priorities which can be used to
discriminate in favour of more important traffic in the event of overload
(though in an underloaded network, the effect of such policies will be
invisible, and may incur no load/work in routers).
The router
service model to provide such classes with different treatment can be as simple
as a priority queuing system, or it can be more elaborate.
Although
best-effort services can support real-time traffic, classifying real-time
traffic separately from non-real-time traffic, and giving real-time traffic
priority treatment, ensures that real-time traffic sees minimum delays. Non-real-time TCP traffic tends to be
elastic in its bandwidth requirements, and will then tend to fill any remaining
bandwidth.
We could imagine
a future Internet with sufficient capacity to carry all of the world's
telephony traffic (POTS). Since this is
a relatively modest capacity requirement, it might be simpler to establish POTS as a static class, which is given
some fraction of the capacity overall. In that case, within the backbone of the
network no individual call need be given an allocation. We would no longer need
the call set-up/tear down that was needed in the legacy POTS; this was only
present due to under-provisioning of trunks, and to allow the trunk exchanges
the option of call blocking. The vision
is of a network that is engineered with capacity for all of the non-best-effort
average load sources to send without needing individual reservations.
3.2.2.1
RSVP
For flows that
may take a significant fraction of the network (i.e. are special and cannot just be lumped under a static class), we need a
more dynamic way of establishing these classifications. In the short term, this
applies to many multimedia calls since the Internet is largely under-provisioned
at the time of writing. RSVP has been standardised for just this purpose. It
provides flow identification and classification. Hosts and applications are
modified to speak RSVP client language, and routers speak RSVP.
Since most
traffic requiring reservations is delivered to groups (e.g. TV), it is natural
for the receiver to make the request for a reservation for a flow. This has the
added advantage that different receivers can make heterogeneous requests for
capacity from the same source. Thus
RSVP can accommodate monochrome, colour and HDTV receivers from a single source
(also see Section 4.2). Again the routers conspire to deliver the right flows
to the right locations. RSVP accommodates the wildcarding noted above.
If a network is
provisioned such that it has excess capacity for all the real-time flows using
it, a simple priority classification ensures that real-time traffic is
minimally delayed. However, if a
network is insufficiently provisioned for the traffic in a real-time traffic class,
then real-time traffic will be queued, and delays and packet loss will
result. Thus in an under-provisioned
network, either all real-time flows will suffer, or some of them must be given
priority.
RSVP provides a
mechanism by which an admission control request can be made, and if sufficient
capacity remains in the requested traffic class, then a reservation for that
capacity can be put in place. If insufficient capacity remains, the admission
request will be refused, but the traffic will still be forwarded with the
default service for that traffic's traffic class. In many cases even an admission request that failed at one or
more routers can still supply acceptable quality as it may have succeeded in
installing a reservation in all the routers that were suffering
congestion. This is because other
reservations may not be fully utilising their reserved capacity in those
routers where the reservation failed.
A number of
specific documents describing the RSVP protocols are: [rsvp], [rsvp-cls] and
[rsvp-gs]
3.2.2.2
Billing
If a reservation
involves setting aside resources for a flow, this will tie up resources so that
other reservations may not succeed; then, depending on whether the flow fills
the reservation, other traffic may be prevented from using the network. Clearly some negative feedback is required
in order to prevent pointless reservations from denying service to other
users. This feedback is typically in
the form of billing.
Billing requires
that the user making the reservation be properly authenticated so that the
correct user can be charged. Billing
for reservations introduces a level of complexity to the internet that has not
typically been experienced with non-reserved traffic, and requires network
providers to have reciprocal usage-based billing arrangements for traffic
carried between them. It also suggests
the use of mechanisms whereby some fraction of the bill for a link reservation
can be charged to each of the downstream multicast receivers.
Whereas RSVP asks
routers to classify packets into classes to achieve a requested quality of
services, it is also possible to explicitly mark packets to indicate the type
of service required. Of course, there
has to be an incentive and mechanisms to ensure that high-priority is not set by everyone in all packets; this incentive
is provided by edge-based policing and by buying profiles of higher priority
service. In this context, a profile
could have many forms, but a typical profile might be a token-bucket filter
specifying a mean rate and a bucket size with certain time-of-day restrictions.
This is still an
active research area, but the general idea is for a customer to buy from their
provider a profile for higher quality service, and the provider polices marked
traffic from the site to ensure that the profile is not exceeded. Within a provider's network, routers give
preferential services to packets marked with the relevant type-of-service
bit. Where providers peer, they arrange
for an aggregate higher-quality profile to be provided, and police each other's
aggregate if it exceeds the profile. In
this way, policing only needs to be performed at the edges to a provider's
network on the assumption that within the network there is sufficient capacity
to cope with the amount of higher-quality traffic that has been sold. The
remainder of the capacity can be filled with regular best-effort traffic.
One big advantage
of differentiated services over reservations is that routers do not need to
keep per-flow state, or look at source and destination addresses to classify
the traffic; this means that routers can be considerably simpler. Another big advantage is that the billing
arrangements for differentiated services are pairwise between providers at
boundaries - at no time does a customer need to negotiate a billing arrangement
with each provider in the path. With reservations there may be ways to avoid
this too, but they are somewhat more difficult given the more specific nature
of a reservation. A good overview of the network service model for
Differentiated Services (DiffServe) is given in [difserv].
Network support
is not supposed to be a major part of the MECCANO project, but it is an
essential ingredient to provide adequate service. We describe here some of the
requirements and components we consider indispensable for MECCANO services. It
is essential that all the main nodes participating in MECCANO conferences have
reasonable connection to the Internet, and that the Internet has reasonable
performance.
The meaning of reasonable, is difficult to determine;
it depends on the performance desired. The key parameters are packets/sec,
variability in packet arrival (jitter in ms), mean transit time of packets,
stability of the Internet Connectivity of certain routes, availability of
multicast in the Internet Provider. These parameters have different impact on
the different services.
In international
services, the different paths often have very different performance
characteristics, moreover, alternate routing may be difficult to arrange
automatically - particularly with multicast. Hence it is essential that the
links are stable enough to have few outages of many seconds during a typical
session. If longer and more frequent interruptions of service take place, it is
very difficult to run a conference.
The normal
Internet topology with multicast provision is called the Mbone. This is a
single topology and has no differentiation between different users. Even if all
conferees have access to the Mbone, there remains the question of whether the
performance is adequate, and whether the demands on the bandwidth are too
great. If all the above are in order, nothing needs to be done to compensate.
Unfortunately, particularly the international Mbone is very variable between
countries, and they have different policies on how much bandwidth they provide
- both nationally and internationally. Thus we often need to supplement normal
Mbone by unicast tunnels. If this is done, we have to be very careful not to
upset the total Mbone topology.
With the present
European networks, the Mbone is often inadequate for reasonable conferencing.
Hence we often construct a significant part of the topology from unicast
routes. Both in MERCI and in MECCANO, we have used the experimental high-speed
networks originally JAMES, and more recently the VPN capability of TEN-155 to
construct a high-quality backbone. We must then construct reflectors at
strategic points to ensure full multicast facilities. If we still have access
to the Mbone at any site, we must ensure, by route filtering and scoping, that
the appropriate Mbone topology is not disturbed.
The next
parameter is throughput - in Kbps or packets/sec per audio stream; here the
requirements depend on the media and quality desired. For audio tools like RAT,
typical bandwidths needed are 8 - 32 Kbps; on good channels, with modern
codecs, the higher of these give good quality audio. For video using tools like
VIC, the corresponding rates are 50 Kbps - 3 Mbps. At the lower bandwidths,
with slowly varying scenes, a few frames/sec can be achieved with QCIF, at the
higher rates, full motion can be achieved at reasonable definition. The optimal
media data rates for specific bandwidth depend also on the level and nature of
channel errors. With audio, data arriving delayed or not at all is dropped.
However, it is possible to provide deliberate redundancy in the talk-spurts to
compensate for the loss. With video, similar errors will impact a whole frame.
For this reason, while inter-frame coding will give much better performance at
low error rates, it can be very inefficient at high ones. For this reason, most
current implementations of tools like VIC do not currently use inter-frame
coding; therefore higher data rates are needed for a given quality. We have
done many measurements on data quality as a function of packet loss. We find
loss rates of 15% still give reasonable quality of audio, with losses up to 40%
tolerable with good use of redundancy. With no inter-frame coding, loss rates
of up to 20% give quite tolerable video.
The next
parameter is variability of delay, called jitter. In most of the audio tools,
one can trade tolerance to jitter against delay. A jitter above a hundred ms
in a replayed packet is so annoying, that this may be taken as an approximate
cut-off point. If most packets have a variability of arrival between 50 and 150
ms, for example, then one can deliberately put in a delay of 150 ms in the
replay buffer. Any packets arriving more than 150 ms late will be dropped.
Similar considerations apply to video. If the delay is made too long, it is
very annoying for fully interactive sessions; it is much less serious for
one-way activities like lectures. A jitter above the cut-off point is exactly
equivalent to packet loss.
The
considerations for shared work-space tools are different. Here because the
individual operations must be kept consistent, some form of Reliable multicast
is normally used. Now it is the total rate of updates, packet loss, and
connectivity that are the important factors. Overmuch packet loss will increase
the traffic level on the network; the load is normally much less than that due
to the audio and video.
So far we have
considered standard use of the
Internet. In fact there are many activities to introduce mechanisms for
providing “Quality of Service” (QoS), as mentioned in Section 3.2. Some of
these rely on mechanisms introduced at the access point of the networks; most
DiffServe algorithms come into this category. Others rely on setting up
reservations throughout the networks; most IntServ algorithms come into this
category. So far none of the regular National or International IPv4 networks
used in MECCANO support such mechanisms. With the next generation of Internet
Protocols, those based on IPv6 [ipv6], there is support for this facility at
the IP level. For this reason, there is starting to be support on experimental
networks running IPv6 for QoS. There is no reason why the same support cannot
be provided on IPv4 networks; it is just not happening.
We would like to
explore in MECCANO the scope for improving the quality of conferencing by
providing QoS support. In view of the above, there will be a deliberate
activity in the project to support IPv6 and its QoS enhancements. This work
will have many aspects. Clearly it will be necessary to provide IPv6-enabled
routers; at the very least they can apply DiffServ algorithms at the borders to
the WANs. It will be necessary to tunnel through any intermediate networks that
support only IPv4. When VPNs are used, as with some of the TEN-155 activity, it
may be possible to use IPv6 throughout.
It is possible to
provide IPv4 enabled applications inside the local areas of conferees, and then
to change to IPv6 at the edges to the wide-area. This approach will be followed
initially, providing only very crude clues to where QoS is to be used - like
favouring audio over video. This can be achieved by prioritising streams in the
router based on the multicast group used with techniques such as Class-Based
Queueing (CBQ) [cbq]. Another aspect will be to make the applications able to
signal their own needs for QoS; thus audio codecs may decide which of their
streams require the better service, and to mark them accordingly. The lower level
software may then assign the different streams to different multicast groups;
the routers may then apply the relevant QoS policies. Because IPv6 provides
support for QoS at the IP level, many operators will not support QoS except on
IPv6-enabled parts of their networks. For this reason, another part of the
MECCANO project will be to ensure that the applications themselves can support
IPv6 directly. In many cases the implementation work required will be carried
out in other projects; the results will be used experimentally also in MECCANO.
Of course we
support the usual aggregation of LAN and WAN technologies which support
multicast, and are normally encountered in organisations. In addition, we will
support two others: unicast ISDN and Direct Broadcast Satellite access. The
salient point of each is discussed below.
Many
organisations, particularly industrial ones, do not support multicast - or will
not let it get through their firewalls. For this reason one useful device that
will be provided is one that does unicast<->multicast conversion. Further
details are given in Section 8. Others will want to participate in MECCANO via
unicast ISDN; this may be because their organisation will not allow direct
Internet access from inside their organisations, or may want to participate
from home. For this reason, we will provide such access facilities; the
gateways needs to provide them are discussed in Section 8.5.
The nature of
participation in multimedia conferences is that it is possible to participate
at different levels of service - and therefore of bandwidth need. It is
possible to participate with only audio - but get much more out of it if one
can also receive video or high quality presentation material. Moreover, we have
already said that the availability of network services is very variable; in
many areas of Western European countries, and in even larger areas when one
goes further East, the bandwidth available to individuals through the Internet
will not support even medium quality multimedia. For this reason, there is
considerable scope for supporting access mechanisms which are not symmetric. In
the future, we expect that mobile radio, xDSL and Cable TV access will become
very useful in this context; during the MECCANO project, we will not use such
mechanisms since we do not have access to them. We will, however, make use of
DBS services.
In a DBS,
equipment at the up-link site is a normal participant of the conference, and
receives all the multicast data streams; the up-link then retransmits all the
normal multicast digital stream via the satellite channel. Any participants via
the DBS system have a DBS receiving terminal which has a built-in multicast
router, and a separate Internet link. If there is no nearby multicast facility
on the Mbone, a unicast tunnel may need to be set up. Normally, as discussed in
Section 3.1, routers must prune any unicast traffic down-stream from them
towards leaf nodes; this uses the symmetric nature of most Internet
connections. In the DBS case, alternative mechanisms must be used. The full
details of the technology will be reported in the Deliverables of WP6, but an
overview is given below. Two approaches to solve the problem were
considered. The first one is based on routing protocol modification and the
other on tunneling.
In the first approach each
routing protocol is modified in order to take into account the unidirectional
aspect of the underlying network. Modifications to protocols such as RIP, OSPF
and DVMRP were proposed and implemented before the start of the MECCANO
project. The modified routing protocols are operational. The experimentation is
described in [udlr]www.inria.fr/rodeo/udlr. However, The second
approach was more attractive: a link layer tunneling mechanism that hides the
link uni-directionality and allows transparent functioning of all upper layer
protocols (routing and above).
Tunneling is a means to
construct virtual networks by encapsulating the data. Broadly speaking, data is sent by the network
layer instead of the data-link layer.
This generally allows new protocols experiments and provides a quick
simple solution to various routing problems by building a kind of virtual
network on top of the actual one. The aim of using tunneling is to make routing
protocols work over unidirectional links without having to provide any
modification to them.
The tunneling approach adds
a layer between the network interface and the routing software on both feed and
receiver sides (or between some intermediate gateways), resulting in the
emulation of a bi-directional satellite link where only an unidirectional link
is available. Packet encapsulation is
hiding the actual topology of the network in order to elude the routing
protocols and make them behave as if there exists a bi-directional satellite
link. The
tunneling mechanism we proposed is described in detail in an Internet draft of
the udlr working group [duros99]. Here follows a short description of the
solution.
Basically, routing traffic
is sent from the receivers to the feed on the virtual link and is later
captured by the added layer interface, which encapsulates it and sends it on
the actual reverse link. The feed station
then decapsulates it and transmits it to the routing protocols as if this was
coming from the virtual satellite link. As a receiver needs to sends a routing
message to a feed, the packet is encapsulated in an IP packet whose IP source
address is the receiver bi-directional address and IP destination address is
the feed bi-directional address. The datagram is then sent to the end point of
the tunnel via the terrestrial network. As it is received by the feed, the
payload of the datagram is decapsulated. The new IP packet that is obtained is
routed according it its destination address. The packet is then routed locally and not forwarded if the
destination address is the feed itself. The IP stack passes the packet to
higher level, in our case the routing protocol.
Similarly to routing
protocols modifications, as they discover feeds dynamically, receivers should
be capable of setting up tunnels dynamically as they boot up. The only way a
receiver can learn the tunnel end point is to define a new simple protocol.
Feeds periodically advertise their tunnel end point (IP address) over the
satellite network. As a receiver gets this message, it checks if the tunnel
exists, if not it creates a tunnel and uses it.
Routing protocols usually
have mechanisms based on timeouts to detect if a directly connected network is
down. If the satellite network is not operational and receivers keep on sending
their routings messages via regular connections, feeds will continue to send
packets on its unidirectional interface. This is undesirable behaviour because
it will create a black hole. In order to prevent this, when receivers have not
received routing messages from the satellite network for a defined time, they
turn their tunnel interface off. As a result, feeds receiving no routing
messages from receivers delete in their routing tables all destinations
reachable via the satellite network.
Having a tunnel between a
receiver and a feed is very attractive because the unidirectional link is
totally hidden to applications. As far as routing protocols are concerned they
have to be correctly configured. For instance, for RIP, a feed must announce
infinite distance vectors to receivers, this way receivers do not take into
account destinations advertised by feeds.
In the MECCANO
project, we will provide as good quality links as we can to any available DBS
up-links. There will certainly be one at INRIA, but there may be ones also at
other sites. We will also equip a number of sites with DBS receivers; this will
certainly include most of the MECCANO partners, but may include other sites
too. There will therefore be a DBS overlay in addition to any other network
facilities provided.
So-called
real-time delivery of traffic requires little in the way of transport protocol.
In particular, real-time traffic that is sent over more than trivial distances
is not retransmittable.
With packet
multimedia data there is no need for the different media comprising a
conference to be carried in the same packets.
In fact it simplifies receivers if different media streams are carried
in separate flows (i.e., separate transport ports and/or separate multicast
groups). This also allows the different
media to be given different quality of service. For example, under congestion, a router might preferentially drop
video packets over audio packets. In
addition, some sites may not wish to receive all the media flows. For example, a site with a slow access link
may be able to participate in a conference using only audio and a whiteboard
whereas other sites in the same conference with more capacity may also send and
receive video. This can be done because the video can be sent to a different
multicast group than the audio and whiteboard.
This is the first step towards coping with heterogeneity by allowing the
receivers to decide how much traffic to receive, and hence allowing a
conference to scale more gracefully.
Best-effort
traffic is delayed by queues in routers between the sender and the
receivers. Even reserved priority traffic
may see small transient queues in routers, and so packets comprising a flow
will be delayed for different times.
Such delay variance is known as jitter and is illustrated in Fig. 3

Figure 3 Network Jitter and Packet Audio
Real-time
applications such as audio and video need to be able to buffer real-time data
at the receiver for sufficient time to remove the jitter added by the network
and recover the original timing relationships between the media data. In order to know how long to buffer, each
packet must carry a timestamp, which gives the time at the sender when the data
was captured. Note that for audio and
video data timing recovery, it is not necessary to know the absolute time that
the data was captured at the sender, only the time relative to the other data
packets.

Figure 4
Inter-media synchronisation
As audio and
video flows will receive differing jitter and possibly differing quality of
service, audio and video that were grabbed at the same time at the sender may
not arrive at the receiver at the same time.
At the receiver, each flow will need a playout buffer to remove network
jitter. Adapting these playout buffers
so that samples/frames that originated at the same time are played out at the
same time (see Fig. 4) can perform inter-flow synchronisation.
This requires
that the time base of different flows from the same sender can be related at
the receivers, e.g. by making available the absolute times at which each of
them was captured.
The transport
protocol for real-time flows is RTP
[schu96-1]. This provides a standard format packet header which gives
media specific timestamp data, as well as payload format information and
sequence numbering amongst other things.
RTP is normally carried using UDP. It does not provide or require any
connection set-up, nor does it provide any enhanced reliability over UDP. For RTP to provide a useful media flow,
there must be sufficient capacity in the relevant traffic class to accommodate
the traffic. How this capacity is
ensured is independent of RTP.
Every original
RTP source is identified by a source identifier, and this source id is carried
in every packet. RTP allows flows from
several sources to be mixed in gateways to provide a single resulting
flow. When this happens, each mixed
packet contains the source IDs of all the contributing sources.
RTP media
timestamp units are flow specific - they are in units that are appropriate to
the media flow. For example, 8kHz
sampled PCM-encoded audio has a timestamp clock rate of 8kHz. This means that inter-flow synchronisation
is not possible from the RTP timestamps alone.
Each RTP flow is
supplemented by Real-Time Control Protocol (RTCP) packets. There are a number of different RTCP packet
types. RTCP packets provide the
relationship between the real-time clock at a sender and the RTP media
timestamps so that inter-flow synchronisation can be performed, and they
provide textual information to identify a sender in a conference from the
source id.
There are a
number of detailed documents on the RTP protocol, which has been adopted both
for ITU and Mbone conferencing. Some of these are:
·
[schu96-1], which gives the packet format for real-time traffic used in
RTP and RTCP.
·
[schu96-2], which specifies the RTP profile for AV traffic
·
[rtpf] There are a whole series of reports, which specify the payload
formats for specific codecs.
IP multicast
allows sources to send to a multicast group without being a receiver of that
group. However, for many conferencing
purposes it is useful to know who are listening to the conference, and whether
the media flows are reaching receivers properly. Accurately performing both
these tasks restricts the scaling of the conference. IP multicast means that no-one knows the precise membership of a
multicast group at a specific time, and this information cannot be discovered;
to try to do so would cause an implosion of messages, many of which would be
lost. A conference policy that restricts conference membership can be
implemented using encryption and restricted distribution of encryption keys;
this is discussed further in Section 9. However, RTCP provides approximate
membership information through periodic multicast of session messages; in
addition to information about the recipient, these also give information about
the reception quality at that receiver.
RTCP session messages are restricted in rate, so that as a conference
grows, the rate of session messages remains constant, and each receiver reports
less often. A member of the conference
can never know exactly who is present at a particular time from RTCP reports,
but does have a good approximation to the conference membership. The is analogous to what happens in a
real-world meeting hall; the meeting organisers may have an attendance list,
but if people are coming and going all the time, they probably do not know
exactly who is in the room at any one moment.
Reception quality
information is primarily intended for debugging purposes, as debugging of IP
multicast problems is a difficult task. However, it is possible to use
reception quality information for rate adaptive senders, although it is not
clear whether this information is sufficiently timely to be able to adapt fast
enough to transient congestion.
The Internet is
very heterogeneous, with link speeds ranging from 14.4 Kbps up to 1.2 Gbps, and
very varied levels of congestion. How
then can a single multicast source satisfy a large and heterogeneous set of
receivers?
In addition to
each receiver performing its own adaptation to jitter, if the sender layers
[mcca95] its video (or audio) stream, different receivers can choose to receive
different amounts of traffic and hence different qualities. To do this, the sender must code they video
as a base layer (the lowest quality that might be acceptable) and a number of
enhancement layers, each of which adds more quality at the expense of more
bandwidth. With video, these additional
layers might increase the frame rate or increase the spatial resolution of the
images or both. Each layer is sent to a different multicast group, and
receivers can decide individually how many layers to subscribe to. This is illustrated in Fig. 5. Of course, if they are going to respond to
congestion in this way, then we also need to arrange that the receivers in a
conference behind a common bottleneck tend to respond together. This will
prevent de- synchronised experiments by different receivers from having the net
effect that too many layers are always being drawn through a common
bottleneck. Receiver-driven Layered
Multicast (RLM) [mcca96] is one way that this might be achieved, although there
is continuing research in this area.
 `
`
Figure 5 Receiver
adaptation using multiple layers and multiple multicast groups
Fundamental to
the transmission of audio and video streams over digital networks is the use of
coders and decoders; their combination is called a codec. These are devices that sample the analogue signals, and
process the resulting digital streams. This processing, which is done in the
codec, will require variable amounts of processing power, and produce output
with different properties. The algorithms used in different codecs are beyond
the scope of this Deliverable. There is a detailed discussion of different
audio and video codecs in [acoder] and [vcoder]. Because it is inevitable that
there are some losses in data transmission, various techniques are invoked to
overcome the impact of errors. Many of these need not be discussed here; they
impact strongly the interaction between the coder and the decoder, but have
little impact on the conferencing architecture. There are some techniques,
however, which do have such impact - particularly if the network
characteristics are variable.
One aspect is
that different codec algorithms have different compression factors; i.e. for a
given picture, different amounts of data are generated. If one part of the
network is able to transmit at one speed without undue network error, and
another has a lower capacity, it may be necessary to use different coding
algorithms in the two regions. To mediate between the two may require decoding
and re-coding (though this may be possible completely in the digital domain).
Devices that carry out this process are called transcoders [amir98].
Another property
of codecs is that they may be scaleable, producing different layers of coding.
A receiver may process one, some or all of these layers. With well-structured
layered coding, processing one layer will provide a minimal quality of media;
processing more layers will provide progressively better quality. If all the
layers are sent over one multicast group, then a layered codec may not be
architecturally different from other codecs for the purpose of this paper.
However, if it is easy for an intermediate node to recognise the different
layers, then it may be easy to provide digitally the equivalent of transcoding.
It is also possible to send different layers to different multicast groups. By
subscribing only to some groups, a receiver may avoid overloading the network,
or its own processor. Alternately, by passing only certain multicast groups, an
active element in the network may ensure the protection of a lower capacity
region. Both these mechanisms do have impact on the architecture of multicast
conferencing. In addition, if the network does not support hierarchical
protection, unequal error protection
has to be added at the transmitter such that the more important layers are
protected by a stronger channel code [scalvico, rs].
Since digital
video has by far the largest data rate of all media, it is essential to use
scalable video coding. This is not only true for video transmission but also
for the processing at encoder and decoder. Especially at the encoder side,
which is usually much more complex than the decoder, scalable software is
essential, if it should be used on various platforms. A scalable coder should
choose its coding algorithms dynamically according to the available processing
power and produce hierarchical bit streams for different transmission rates
[scalvico].
Codec algorithms
are deeply concerned with providing the optimal digital rendering of the media
streams in terms of certain criteria. These criteria certainly include faithful
reproduction, minimising bandwidth, reducing computation, and robustness to
errors. The robustness can be provided by providing various forms of redundancy
[rosen98]. The redundancy may be independent of the contents; there are various
codes which can recover from successive bit errors, for example. Alternately
one can use knowledge of the characteristics of the media to limit the amount
of redundancy transmitted. For example, with speech, if the previous audio
frame is similar in characteristics to the current frame we do not bother to
send a redundant copy; receiver-driven error concealment will provide an
acceptable alternative in case of loss. In a similar manner, we could use
knowledge of the characteristics of a speech signal to determine the priority
to insert into the IPv6 flow label header. This would allow a router with
class-based queuing to give priority to those packets which are perceptually
more important. This is the audio analogue to giving different QoS to MPEG P
and I frames [mpeg].
Applications other than audio and video have evolved
in Internet conferencing, conferencing, ranging from shared text editors (NTE
[han97]) to shared whiteboards (WB [floy95], DLB [gey98]) and support for
dynamic 3D objects (TeCo3D [mau99]). Such applications can be used to
substitute for meeting aids in physical conferences (whiteboards, projectors)
or replace visual and auditory cues that are lost in teleconferences (e.g.
raising hands [mates], voting [mates, mpoll] and a speaker list); they can also
enable new styles of joint work.
Non-A/V applications currently have vastly different
design philosophies. This leads to a multitude of architectures and proprietary
protocols both at the transport and at the application level. It is therefore a
challenging task to combine them into a homogeneous teleconferencing toolset.
Especially the development of generic services, like recording and playback of
conferencing sessions, is currently impossible. These problems can be traced to
two related areas: reliability and application layer protocols for non-A/V
applications.
Many non-A/V applications have in common that the
application protocol is about establishing and updating a shared state. Loss of
information is often not acceptable, so some form of multicast reliability is
required. However, the applications' requirements differ. Some applications
just need a guarantee that each application data unit (ADU) eventually arrives;
others require that the ordering of the ADUs transmitted by a single
participant will be received in order. Applications might even demand that the
total order of all ADUs send by all participants is preserved. Additionally
applications have different requirements on the timeliness with which the
packets need to be delivered.
Closely related to the reliability requirements of
an application is the problem of which part of the system is responsible for
providing the reliability. On the one hand there are approaches to provide
reliability at the transport level (layer 4). These approaches basically
provide an interface similar to TCP. The positive aspect of realising
reliability in this way is the simplicity of the interface and a very clean
(layered) software architecture.
On the other hand approaches exist which require the
application to be network aware and
help with repairing packet loss. This is especially desirable if the repair
mechanism does not rely exclusively on the simple retransmission of the lost
packet(s) but also on application level information. In a shared whiteboard,
for example, it might be desirable to repair packet loss, which relates to the
state of the pages visible to the local user on a higher priority than packet
loss for other pages. An additional benefit of being network aware is the possibility of mapping ADUs to transport PDUs
on a one-to-one basis (application level framing, ALF [clark90]). If each transport
PDU carries information which is useful to the application independent of any
other transport PDUs, the application can usually process them out of order,
significantly increasing the efficiency for some applications.
A possible solution to the problem of diverse
approaches to provide reliability in a multicast environment could be a
flexible framework for reliable multicast protocols. As proposed by the
Reliable multicast Framing Protocol Internet-Draft [crow98], a framing protocol
could be used to provide a similar service to different reliable multicast
approaches as RTP provides to different A/V encodings. Ideally this would
result in a flexible, common API for reliable multicast where each application
can choose from a set of services (such as one-to-many bulk transfer, or
many-to-many user interaction).
The question of how to realise the reliability for
different applications, given the wide range of reliability requirements, is
one of the topics where work is still in progress in the IRTF research group on
Reliable multicast [rmrg]. Other aspects of reliable multicast, which are not
well understood, include how to provide congestion control in a multicast
environment. As these issues are considered essential elements, standards track
protocols are not expected before these can be solved.
The second reason why non-A/V applications are so
diverse, and services like generic recording are currently not possible, is the
lack of a commonly accepted application level protocol (an RTP-like protocol framework
for non-A/V applications). While the need for such a protocol has
been expressed by many application developers, it is currently not addressed by
any standards track activities.
Most conferencing solutions, which allow for
collaboration between participants in a conference, provide either a single
application distributed amongst the participants (Application Sharing) or a distributed data set on which all may
work (Workspace Sharing).
Some conferencing tools allow additionally for
text-based communication exchange, file transmission, acquisition of
distributed information and other mechanisms to distribute or collect
(non-audiovisual) information in the context of a running conference.
As shown in Fig. 6, Application Sharing basically works by distributing the user interface of a single application.
While that program is still running on a single machine, it may now be seen by
multiple conference participants. If permitted by the user actually running the
application, it may also be operated by several users - either simultaneously
or sequentially, depending on the chosen floor control policy.
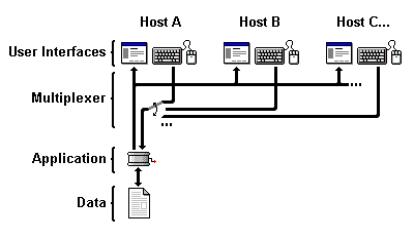
Figure 6 Data
flow in an Application Sharing
scenario
On the other hand, Workspace Sharing tools distribute a common data set among the
participants of a conference, as illustrated in Fig. 7. Each partner has a
local representation of the shared workspace and may modify it at will
(depending on the access control policy). By the exchange of messages, the
sites try to achieve a consistent workspace state.
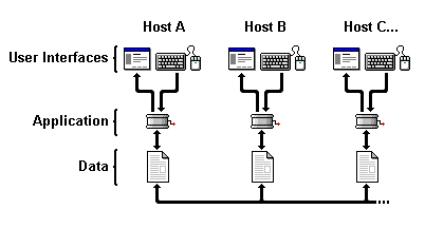
Figure 7 Data
flow in a Workspace Sharing scenario
The shared
workspaces described within this chapter allow several participants to
modify simultaneously one or multiple
documents in the context of a running
conference (synchronous collaboration). There are other (asynchronous)
systems [bscw][linkworks] defining a workspace
as a set of documents (in terms of
files created by an arbitrary non-distributed application) which can be consecutively
modified by the members of a working group. In contrast to a mere distributed
file system, these tools implement versioning and access control, support
routing and workflow mechanisms, provide electronic signatures for individual
documents, allow for approval and disapproval of modifications, keep track of
deadlines and the status of documents and inform group members of any document
changes they might be interested in.
Tools for Application
Sharing and Workspace Sharing
share a number of common issues.
5.2.1.1 (Adaptable) Reliability of Message Transfer
In contrast to real-time multimedia streams,
where lost packets just degrade the
perceivable quality of an audio/video transmission, application and
workspace-sharing techniques usually require a certain level of transport
reliability, at least. Otherwise, users would be faced with incomplete
documents or antiquated application states and actually be unable to
collaborate.
Only few applications (e.g. multicast file
transfer) need every packet be
delivered reliably (and in the original order), most systems want all
participants to share a common and actual
status (e.g. the current position of a shared mouse pointer) - packets carrying
obsolete status information (e.g., former pointer positions) may get lost
without adverse consequences.
Some tools designed for Distributed Interactive Simulation assign priorities to certain status records (depending on their importance
for a successful collaboration) and require only high-priority information to be
delivered reliably. While a successful reception of low-priority data may
increase the quality, it is not vital for the simulation as a whole.
In the extreme case, some battlefield simulations
do without any mechanism to achieve a reliable transmission, since most aspects
of such a simulation can be calculated from physical models and only behavioural changes have to be transmitted. As these are
rare compared to the capacity of the networks and computers used, they can be
sent multiple times assuming that eventually every participant will have got
the information at least once.
5.2.1.2 Scalability
Most application and workspace-sharing tools
support a small number of users only - with numbers ranging from two to a few
tens - often limited by the transport protocol used. multicast applications
have the advantage, in principle, of supporting an unlimited number of
participants, as long as these sites only receive packets passively from other
active participants and do not try to send packets themselves. In practice, current
techniques for reliable multicast still limit the number of participants to a
few hundred.
5.2.1.3 Floor and Access Control
If multiple conference participants may operate a
shared application or modify objects in a shared workspace, there is a need to
coordinate these activities.
Some systems use the concept of an explicit floor holder to restrict activities to a
single user - with varying policies for the initial assignment of the floor and different (social) protocols
for passing it between session participants.
Multicast tools usually do without such a concept
as it does not mesh well with the idea of lightweight
multicast sessions. In a multicast environment it is often better to forbid
or permit the modification of certain objects - or not to implement any access
restrictions at all.
5.2.1.4 Consistency of State Information among Session Participants
Packet loss and different packet transit times
may lead to inconsistent states at individual sites causing problems if these
partners start operating a shared application or modifying a shared workspace
themselves based on their improper state information.
Floor-controlled systems often check (and establish)
workspace consistency when passing the floor to a new floor-holder - other
session partners may continue with an inconsistent state as they must not apply
any modifications.
Centralised approaches rely on one (or multiple)
central servers holding the actual state which all other session participants (clients) are bound upon. Clients may use
these servers to update their own status information or check for consistency
before requesting a status change themselves.
Multicast tools (without any access restrictions)
often use global clocks to identify the latest status of a given object and
impose a strict ordering on operations from several users. In combination with a message counter (and some heartbeat mechanism) to detect packet loss these clocks help
individual sites to converge to a common
(workspace) state.
5.2.1.5 Integration of late joining
Participants into a running Conference
Usually, not all conference partners participate
in a conference from the beginning - it often happens, that some users join a
session which is already running. For an application sharing session this
implies that the late user first has
to receive the actual contents of the shared screen in order to be able to interpret mouse movements and operations
properly. Similarly, in a shared workspace environment the late user has to obtain the actual workspace status before she/he
will be able to apply any modifications.
5.2.1.6 Behaviour in case of Network Partitioning
A special case occurs, when certain sites become
disconnected temporarily from the remaining group, e.g. because of a router
failure. In a floor-controlled system this might lead to the situation, that
the floor holder gets disconnected and, thus, prevents all other participants
from operating a shared application or modifying a shared workspace. Some tools
solve this problem by automatically or manually reassigning the floor to a new
participant (e.g. in an application-sharing session the floor is usually given
back to the person actually running the shared application).
5.2.1.7 Synchronisation with other Media Streams
When used in the context of an audio/video
conference, it is sometimes necessary to synchronise the application or
workspace-sharing session with A/V streams transmitted simultaneously to
prevent a speaker talking about a state not yet seen by his/her listeners. At
present, however, we know of only one system which provides such synchronisation,
the commercial product MarratechPro [marra].
5.2.1.8 Recordability
If an application or workspace-sharing tool
requires some kind of transport reliability, it is no longer sufficient for a
conference recorder just to store any incoming packet - instead, it has to understand the protocol, at least, in
order to detect packet loss and take the appropriate measures (such as to
request the retransmission of any lost packet).
Depending on the actual application, a conference
recorder might need even more intelligence
- e.g. for late joining a running
conference and acquiring enough information to successfully perform the
recording from then on.
Additional paradigm-specific issues are mentioned
in the next two sections.
As mentioned above, application sharing basically works by distributing the user
interface of a single application; any changes in the appearance of a running
application (e.g., a moving mouse pointer, new contents of a document window,
any dialogue windows or menu boxes that appear, or interface elements that
change their look when being used) are reported to all participants of a
sharing session. If the session further supports the remote operation of a
locally running program, any mouse movements and key presses performed by a remote
conference partner must be sent back and fed into the application as if they
had originated from the local machine. It depends on the chosen policy whether
all other partners may simultaneously operate a shared program or whether the
right to control it is restricted to one participant at a time. The former
simplifies sessions with frequently changing operators, the latter avoids any
confusion resulting from multiple users trying to operate an application
simultaneously.
The most important advantage of application sharing is its concept of
working with arbitrary group-unaware
applications. As a consequence, there is no need for the development of new
(group-aware) tools - the user may continue using his/her favourite legacy
application instead. That is, provided that the programmer has used officially
documented programming interfaces only. It is often the case, where this has
not been done, that it is not possible to share action games and other
real-time applications because they rely on special programming tricks.
Session set-up and control is provided by a
different program (a session manager)
which is independent of the shared application itself. Sometimes, this session
manager also comes with additional group-aware
tools such as a shared whiteboard, a text-based message exchange (chat) or a
file transfer feature.
Depending on how they distribute the visual
appearance of a user interface, application-sharing
environments can be classified into two main categories: view-sharing and primitive-sharing
environments.
A view-sharing
(sometimes called screen-sharing)
environment takes screen snapshots from the system running the shared
application and sends them as a bitmap to all other participants. Such a
technique is simple to implement and relatively easy to keep
platform-independent. An important implementation of this concept is the
Virtual Network Computing (VNC) [vnc], developed by AT&T Laboratories
Cambridge (see below).
However, most implementations follow the primitive-sharing paradigm and
distribute graphics primitives which then have to be rendered at each site
individually. Due to its similarity to the way in which the X Window system
works, so called X multiplexers were
the first systems which implemented this approach. Today, numerous such systems
exist (XTV [aw99], Hewlett-Packard's SharedX [garf], Sun's SharedApp [sunf] to
mention just a few examples) for the UNIX platform and for IBM-compatible PCs
running Windows (Microsoft NetMeeting [netm] and other T.120-based tools, see
below), but most of them are platform-dependent as the graphics primitives used
for distributing an user interface usually resemble corresponding library calls
and their parameters on a given platform. An important exception from this rule
is the JVTOS system [froitz] which was developed during the RACE project CIO to
provide cross-platform application sharing between Sun and SGI workstations,
Apple Macintosh computers [wolf] and IBM-compatible PCs running Windows.
5.2.2.1 Issues
This section addresses a few problems of application-sharing environments in
addition to those mentioned in Section 5.2.1. See also [begole].
Screen resolution and
colour model
Since application
sharing works by distributing the graphical user interface of an
application, each partner's screen resolution and colour depth should be
compatible with that of the system running the shared application. Otherwise,
parts of a program's window might fall outside the available screen area or
colours may look considerably different at certain sites.
Centralised design
Application sharing sometimes suffers from its
client-server model: a single (server) site running the actual program
distributes its user interface to one or multiple client sites which may for
their part operate the shared application - if permitted. Any files needed
while running the application have to be stored on the server first - and any
results from the run have to be distributed to the participants again (which is
usually done outside the sharing session). If the central server gets
disconnected, other partners are unable to continue with their work and have to
wait for the server to become available again. Similarly, working with an
application is limited to the life-time of a conference session for remote
partners - unless they get all the files and install the application locally as
well, there is no possibility to continue with their work as soon as the
session has finished.
What-you-see-is-what-I-see
(WYSIWIS)
Both an advantage as well as a disadvantage of application sharing is the what-you-see-is-what-I-see effect: every
conference participant has the same view of a shared application, there is no
possibility of browsing through a document or
experiment with other settings without requiring all other partners to follow
these activities. While such a behaviour is explicitly desired during tutorial lectures, it may become
cumbersome in distributed workgroup
sessions.
No concurrent work
An important side-effect of WYSIWIS behaviour is
the restriction to a single position in a document. There is no possibility for
the members of a group to work on different parts of a document simultaneously
by means of application sharing.
Despite these problems, application sharing is
still the most important form of computer-supported collaboration as it can be
used with many (collaboration-unaware) legacy applications.
5.2.2.2 Standards and Implementations
We briefly describe the ITU T.120 family of
standards and some implementations.
T.120
The International Telecommunication Union (ITU)
T.120 standard family [t120] contains a series of communication and application
protocols and services that provide support for real-time, multipoint data
communications - including a broad range of collaborative applications, such as
desktop data conferencing, multi-user applications, and multi-player games.
While the standard itself also supports
multipoint data delivery (even using IP multicast by means of a multicast adaptation protocol (MAP),
tools with T.120 data conferencing capabilities still need a Multipoint Control Unit (MCU) for sessions
with more than two participants as the ITU standard family H.32x used for
audio/video conferencing still lacks multicast functionality.
NetMeeting
NetMeeting [netm] is an integrated H.32x and
T.120-compliant conferencing system including audio/video conferencing, a
text-based chat feature, a simple whiteboard and both program and desktop
sharing. Over the internet, conference partners may be called by specifying
their (numeric or symbolic) IP address or by looking them up (based on their
electronic mail address) in an Internet
Location Server.
While most of the components can also be used in
conferences with more than two participants, audio/video communication can only
be done between two partners (although several of these pairs can exist
simultaneously during a session).
Since NetMeeting offers a number of features,
runs stable, has an intuitive graphical user interface and is available free of
charge, it has become the de-facto standard for ITU-based video and data
conferences.
CIO JVTOS, MaX
The Joint-Viewing
and Tele-Operation System JVTOS is a cross-platform application-sharing
tool based on the X Windows protocol. Due to its design and by means of X
protocol converters it is possible to view and control X Windows applications
(running on a Sun, HP or SGI workstation) from a Macintosh computer or an
IBM-compatible PC running Windows, or vice-versa [ciojvtos, max].
Virtual Network Computing
(VNC)
An important implementation of the screen-sharing paradigm is the Virtual
Network Computing system available from AT&T Labs Cambridge. Instead of
transmitting graphics primitives in order to share the user interface of a
single application, a VNC server shares its complete desktop (on a bitmap
basis) with one or multiple clients which may for their part operate the whole
server - if permitted. Servers exist for a number of platforms including SunOS,
LINUX, Windows, MacOS and even WindowsCE; clients can be run on any platform
supporting Java as VNC also contains a Java-based client implementation [vnc].
In contrast to application-sharing environments, workspace-sharing tools distribute a common data set (the workspace) among the participants of a
conference, allowing every partner to view (and possibly edit) his/her own part
of a shared document independent of other users - if permitted. Every site has
its own local representation of a shared workspace and may continue working
with it even after other sites have become disconnected or left a conference.
One of the primary duties of a workspace-sharing protocol is therefore to keep
the individual (local) representations consistent with those at other sites and
let them all converge to a common global shared
workspace.
In principle, people participating in a workspace-sharing session may use
different applications to work on the common data set. For the time being,
however, workspaces are still application-specific: in order to be able to
examine and modify a shared workspace
the same tool has to be used at each site.
The lifetime of a shared workspace is determined
by the period of at least one running instance of the corresponding application
- i.e., as soon as all conference partners have left the conference, the
workspace is lost. While some tools allow saving and (re) loading the contents of a workspace, there are no means
for merging any changes applied to the saved data outside any session.
A new approach, which is currently being
developed in the context of MECCANO, decouples the shared workspace from its applications and allows its objects to be
deposited in an independent persistent store. A number of these stores then
form a flexibly extensible federated
workspace providing an environment for generic
workspace sharing.
5.2.3.1 Issues
This section briefly describes a few problems
shared-workspace applications have to deal with apart from those already listed
in Section 5.2.1.
Application-specific
Workspaces and Protocols
Most of today's workspace-sharing tools use their
own proprietary data and protocol specifications. The workspace itself (and the
set of operations defined for its objects) is then only implicitly defined in
terms of that protocol making it difficult to use (parts of) existing
implementations for different purposes (i.e. other kinds of documents).
Behaviour in case of
Network Partitioning
All systems allowing each group to continue with their conference (although with a
smaller number of participants) when a network gets partitioned face the
problem of having to recombine the states of every subsession and form a common
state as soon as the individual groups become connected again. Several
solutions exist which are based on a global time associated with every object's
state and enforce a consistent workspace by using younger state information
only. Other approaches exploit the similarity of this problem to the situation
of a late joining person with a
non-empty workspace which has to be made consistent again.
Incompatibilities between
versions of a protocol (or workspace)
Shared-workspace applications often run into
problems when the specification of objects within a workspace and/or the
sharing protocol itself are changed and not all participants immediately
upgrade to the new version. Today's tools require the whole workspace (i.e. all
instances of the corresponding application) to be shut down and then restarted
using the upgraded version only.
5.2.3.2 Implementations and Developments
For MECCANO, workspace
sharing is of higher importance than application
sharing. Within the project, the following tools are used and/or developed:
Shared Whiteboard (wb and
wbd)
The whiteboard wb was originally developed at LBL as a test environment for scalable reliable multicast (SRM)
[floy95]. As the source of wb was never released and the exact protocol never
published, wbd was developed for the
PC platform by Julian Highfield at Loughborough University from an analysis of
the wb protocol [rasmus] performed by Lars Rasmusson in 1995. Wb has become an
important tool for visual presentations over the Mbone - despite the lack of
many important features. Although there are numerous other shared whiteboards
today, none of them has ever found such a widespread use.
UCL Network Text Editor
(NTE)
NTE is a shared text editor designed for use on
the Mbone. Many people can (if they wish) edit the same document simultaneously.
Unless a conference participant locks a block of text, anyone else in the
session can edit that text or delete it [nte].
Authoring-on-the-fly
(AOFwb)
AOFwb is the combination of a graphical
whiteboard with a tool for tele-presentations. Presentations may be prepared
using AOFwb and then distributed among the receivers where a companion tool
(AOFrec) is responsible for receiving and displaying these documents - page
changes and telepointer movements are still controlled by AOFwb [lien98].
Distributed Lecture Board
(dlb)
Basically, the Distributed Lecture Board dlb [gey98] is an enhanced whiteboard
tailored to the needs of synchronous teleteaching. Different media are
integrated in an easy-to-use interface. The dlb provides flexibility for the
use of media, support for collaborative group work and will be integrated in an
overall teaching environment which will support most of the synchronous
teleteaching requirements (construction, transmission, recording, retrieval,
playback, and preparation of lectures and teaching materials).
dlb uses a SGML-like format for its documents and
extends the classical functionality
of a shared whiteboard by supporting annotations and providing mechanisms for
voting, online feedback and attention. It is also network-compatible with the
AOF whiteboard.
The most interesting feature, however, is the
possibility to record and playback dlb sessions using a VCR on-demand service.
TeleCanvas
TeleCanvas [rozek96] is a Java-based (and
therefore rather platform-independent) shared whiteboard that tries to combine
a hierarchical workspace model with a simple transaction model in order to
realise a distributed undo/redo feature. A multi-centred approach guarantees
workspace consistency combined with strict access control while still
maintaining scalability with respect to the number of passive (i.e. listening) number of participants.
TeleStore
Based on the lessons learned from TeleCanvas, a
new approach to generic workspace sharing
is currently being developed in the context of MECCANO. An
application-independent specification of the shared workspace allows any tool that conforms to this
specification to work on a distributed data set. Servers allow for the
persistent storage of workspace data, and distributed garbage collection mechanisms
remove objects which are no longer used. A protoype-based inheritance scheme as
part of the data specification helps keeping different versions of the
workspace compatible with each other even when these are used within the same
session. A local caching concept combined with well-defined behaviour in case
of transaction failures (which is consistent with a user's expectation)
provides a high degree of robustness against network and server failures while
still offering enough responsivity to be used for interactive applications.
As for TeleCanvas, a separate transaction model
forms the basis for
·
distributed
undo/redo mechanism;
·
robust
combination of different workspace states after a temporary network partition;
·
simplified
recording and playback of a given session.
The design and implementation of TeleStore are
being done as part of a PhD thesis.
Conferences come
in many shapes and sizes, but there are really only two models for conference
control: lightweight sessions and tightly coupled conferencing. For both models, rendezvous mechanisms are
needed. Note that the conference
control model is orthogonal to issues of quality of service and network
resource reservation, and it is also orthogonal to the mechanism for
discovering the conference.
Lightweight
sessions are multicast based multimedia conferences that lack explicit
conference membership control and explicit conference control mechanisms. Typically a lightweight session consists of
a number of many-to-many media streams supported using RTP and RTCP using IP
multicast. (There is some confusion on the term session, which is sometimes
used for a conference and sometimes for a single media stream transported by
RTP. In this paper, we prefer to use
the less ambiguous term conference except
where existing protocols use the term session.) Typically, the only conference
control information needed during the course of a lightweight session is that
distributed in the RTCP session information, i.e. an approximate membership
lists with some attributes per member.
Tightly coupled
conferences may also be multicast based and use RTP and RTCP, but in addition
they have an explicit conference membership mechanism and may have an explicit
conference control mechanism that provides facilities such as floor control.
The most widely
used tightly coupled conference control protocols suitable for Internet use is
those belonging to the ITU's H.323 family
[h323]. However it should be
noted that this is inappropriate for large sessions where scaling problems will
be introduced by the conference control mechanisms.
In order to
address this, the ITU has standardised H.332 [h332]; this is essentially a
small tightly coupled H.323 conference with a larger lightweight-sessions-style
conference listening in as passive participants. It is not yet clear whether H.332 will see large-scale
acceptance, as its benefits over a simple lightweight session are not terribly
obvious. It seems likely that
lightweight sessions combined with stream authentication (see Section 9.3)
might be a more appropriate solution for many potential customers.
The Real-Time Stream-control
Protocol (RTSP) [schu98] provides a standard way to remotely control a
multimedia server, such as those discussed in Section 10. While primarily aimed at web-based
media-on-demand services, RTSP is also well suited to provide VCR-like controls
for audio and video streams, and to provide playback and record functionality
of RTP data streams. A client can
specify that an RTSP server plays a recorded multimedia session into an
existing multicast-based conference, or can specify that the server should join
the conference and record it.
An alternate approach is the
one adopted for many traditional distributed object computing (DOC) middleware
by the communications industry. This uses CORBA and Java RMI support/response
as the semantics for distributed applications. Since real-time multimedia
applications require transmission of continuous streams of audio and video
packets, there are stringent performance requirements for streaming data; these
often preclude DOC middleware from being used as the transport mechanism for
multimedia applications. For instance, the CORBA Internet Inter-ORB Protocol
(IIOP) implemented over TCP is inefficient for audio and video transmission and
makes multicast distribution impossible. However, the stream establishment and
control components of distributed multimedia applications can benefit greatly
from the portability and flexibility provided by middleware. To address these
issues, the Object Management Group (OMG) has defined a specification for the
control and management of A/V streams, based on the CORBA reference model.
The CORBA A/V streaming
specification defines a model for implementing a multimedia-streaming
framework. This model integrates
·
well-defined modules, interfaces, and semantics for stream establishment
and control
with
·
efficient transport-level mechanisms for data transmission.
The OMG environment does not
include multicast; however, this is not necessarily a requirement for the A/V
control - provided the media transport protocol does allow multicast. The
framework provides the following flexibility:
Stream
endpoint creation strategies: Many performance-sensitive multimedia applications
require fine-grained control over the strategies governing the creation of
stream components.
Transport
protocol: The OMG streaming service makes no assumptions about the transport
protocol used for data streaming. Consequently, the stream establishment
components in the A/V streaming service provided flexible mechanisms that allow
applications to define and use multiple transport endpoints, such as sockets
and TLI, and multiple protocols, such as TCP, UDP, RTP, or ATM.
Stream
control interfaces: The A/V streaming framework provides flexible
mechanisms that allow designers of streaming services to define their own
stream control interfaces. In particular the existing stream control protocols
such as RTSP may be used for implementation of their operations.
Managing
states of stream supplier and consumer: An important design
challenge for developers is designing flexible applications whose states can be
extended.
In summary the
OMG A/V streaming model goals are the following: definition of standardised
stream establishment and control mechanisms, supporting multiple transport
protocols, and various types of sources and sinks.
There are several
basic forms of conference discovery mechanism. The conferences can be announced
in a broadcast mode, individuals can
be invited in real time, or information about the session can be provided
off-line – by putting the information in a depository or sending it by e-mail.
Each is described briefly below. Information on the security aspects of Session
Initiation is provided in Section 9.3.
One method of
announcing sessions is to multicast the session description on a well-known
multicast port, with a specific scope, using the Session Announcement Protocol
(SAP) [han99-4]. The announcement includes some information (like the Organiser
of the conference), some authentication information and the Session Description
defined in the Session Description Protocol (SDP) [han98]. People wishing to
participate in a particular conference must then listen for the SAP
announcement, and start up their tools with the SDP details provided. A number
of automated tools (e.g. SDR [sdr]) have been developed which can receive the
multicast session descriptions, browse through all sessions currently being
announced and then start up the relevant media tools. An important aspect is
that if the announcement of the message is received, there is a high
probability that the session itself can be joined; this is because the
advertisement uses the same scope as the session.

Figure 8 Joining
a lightweight multimedia session
This mechanism
can also be applied to advertised tightly coupled sessions, requiring only
additional information about the mechanism to use to join the session. However, as the number of sessions in the
session directory grows, we expect that only larger-scale public sessions will
be announced in this manner; smaller, more private, sessions will tend to use
direct invitation rather than advertisement.
Not all sessions
are advertised, and even those that are advertised may require a mechanism to
invite explicitly, but in real-time, a user to join a session. Such a mechanism
is required regardless of whether the session is a lightweight session or a
more tightly coupled session, although the invitation system must specify the
mechanism to be used to join the session.
Since users may
be mobile, it is important that such an invitation mechanism is capable of
locating and inviting a user in a location-independent manner. Thus user addresses need to be used as a
level of indirection rather than routing a call to a specific terminal. The invitation mechanism should also provide
for alternative responses, such as leaving a message or being referred to
another user, should the invited user be unavailable.
The Session
Initiation Protocol (SIP) [han99-1] provides a mechanism whereby a user can be
invited to participate in a conference.
SIP does not care whether the session is already ongoing or is just
being created. It does not care whether the conference is a small tightly
coupled session or a huge broadcast - it merely conveys an invitation to a user
in a timely manner, inviting them to participate, and provides enough
information for them to be able to know what sort of session to expect. Thus although SIP can be used to make
telephone-style calls, it is by no means restricted to that style of
conference.
It is also
possible to use off-line mechanisms for providing the information on up-coming
sessions. One method is to send the information by e-mail; mechanisms for
parsing e-mail and starting sessions automatically have been provided [hin96].
While this is an adequate method, it really needs to be provided in a generic
way, so that it can be parsed automatically by the mail systems. Since a
special MIME type has been defined for specifying SDP, it would be best to use
this for all implementations passing SDP in messages. It is then possible to
provide a MIME Plug-in for each e-mail tool, to parse automatically this
particular MIME type and launch the tool. We plan to provide this functionality
in MECCANO from a WWW browser. It is also desirable to provide a mechanism for
obtaining listings of all sessions currently available, or announced for a
certain interval.
Alternately the
information can be put into a repository known to the potential participants.
The information can then be extracted at will by the potential participants.
This mechanism is convenient if potential participants can be expected to
access the directory sufficiently often. A combination of the use of ordinary
e-mail to announce the existence of a conference, together with a directory
mechanism, will probably be the most popular for a large class of applications.
Specialised Web-based tools already exist which allow the browsing through
lists of conferences, together with client plug-ins that can extract the
relevant Session Description and start up the tools. There is still a potential
problem mentioned in Section 3.1.2. If the Session Announcements are made
privately, the address allocation is not necessarily unique; two independent
announcements may be made of different conferences on the same multicast
address/port. If the address allocation by the announcer is made randomly, this
is unlikely to occur – and will be easily detected. Moreover, the MMUSIC group
is addressing this problem at the moment; any solutions it develops will also
be incorporated in the MECCANO architecture. Multicast sessions are
scope-limited; hence although an announcement may be retrieved, it does not
follow that the retriever can participate in a particular session. Finally, use
of a repository can lead to a single point of failure – the availability or
accessibility of the repository. It is possible to ameliorate this problem by
putting the announcements in several depositories; this is comparable with the
running of a primary and several secondary DNSs in the Internet.
Neither of these
mechanisms will scale well to very large conferences, because of the potential
number of messages or depository accesses. However this is just the environment
where SAP is particularly useful. In any case, it is not clear that we have the
tools to manage really large conferences.
Many of the
activities in multimedia conferencing involve synchronisation or control
between different processes in the same or different processors. A number of
general-purpose systems have been developed to meet this need like CORBA [cor].
These can be used, in fact one of the systems mentioned in Section 10.5 does
indeed use CORBA. However for most of the purposes described in this report, the
performance of CORBA is too poor, and the functionality too general purpose,
rather than tailored to the multimedia applications. For this reason we use, in
general, Mbus which is designed to synchronise and mediate between real-time
processes in one machine – or between machines where negligible delay or error
can be expected. The characteristics of Mbus are discussed below.
The Message Bus
(Mbus) [ott] infrastructure has been designed to simplify development of
complex communication systems intended to enable and augment interactive
human-to-human (tele)co-operation. Such system may include (typically
workstation-based) user terminals (as designed in WP4) as well as various types
of interworking units (WP6) and other management entities (partially developed
in the context of WP7 but to a large extent beyond the scope of the MECCANO
project).
In our abstract
system concept, the functionality of any conferencing system considered in
MECCANO can be broken into a variety of components. These include but are not
limited to media engines, user interfaces, conference control, and modules
providing administrative mechanisms. Depending on the type of conference and
the type of system, some or all these components may need to act in a closely co-ordinated
fashion. Individual tools may be separated logically and physically into their
respective engines and user interfaces that need to communicate to convey user
actions and system responses back and forth. Systems may also have various
media engines controlled by a single user interface and thus require mechanisms
to simultaneously control these engines. Also, media engines may need to
co-ordinate themselves e.g. to synchronise audio playback with presentation of
video streams to achieve lip synchronisation. Finally, in tightly coupled
conferences or IP telephone calls, dedicated entities may perform conference
control functions and may need to closely interact with other system components
to make them adapts their behaviour according to the conference state.
Altogether, local co-ordination is needed to achieve coherent system behaviour
in response to user actions as well as interaction with other conferencing
systems.
While horizontal
control protocols (such as SCCP) are intended to synchronise state between
communicating systems (inter-system protocol), vertical control protocols serve
intra-system co-ordination. The Message Bus shall provide an infrastructure for
vertical co-ordination based upon mechanisms for inter-process communication
(IPC).
It is designed
to satisfy the following needs:
·
support
a modular system design;
·
simplify
using building blocks from different sources through well-defined interfaces;
·
enable
efficient independent development and testing;
·
allow
for independence of programming languages;
·
maximise
re-usability of components in different systems as well as different system
types;
·
support
separation of engines from user interface;
·
enable
easy system extensibility (at run time);
·
not to
prescribe system design or mandate certain components;
·
allow
for efficient and low-overhead communication;
·
be
robust against partial system failures; and
·
support
monitoring of system functions for debugging.
The Mbus
infrastructure logically consists of two components: a transport infrastructure
that provides message transfer, addressing, and basic bootstrap as well as
awareness mechanisms and a semantic layer that is defined through the abstract
services of the communicating modules. Within the MECCANO project, semantic
layers is defined for call and rudimentary conference control services, control
of selected media engines and their user interfaces, and for simple user
preferences/policies.
Systems to be
built based upon the Mbus infrastructure include multimedia terminals and
various types of (multimedia) gateways.
As a basic
service, the Message Bus provides local (intra-system) exchange of messages
between components that attach to the Mbus (Mbus entities). A local system is
typically expected to comprise exactly a single host, but a local system may
also extend across a network link and include several hosts sharing the tasks;
a local system must not extend beyond a single link. Message exchange takes
place using UDP datagrams; UDP datagrams are either sent via unicast to a
single Mbus entity or are multicast using host-local or link-local scope
(depending on far the system reaches).
For
point-to-point communications, message delivery is optionally performed
reliably; i.e. acknowledgements and retransmissions take place at the Mbus
transport layer. All multicast communication is performed unreliably.
Point-to-point and multicast communication are not distinguished by the
transmission mechanism employed at the IP layer but rather by the qualification
of the Mbus destination address (briefly described below).
In addition to
basic message transmission, the Mbus transport provides mechanisms for Mbus
entities to automatically determine the availability and the address other Mbus
entities as well as an entity's failure. Based upon these functions, a
bootstrap procedure is defined that allows Mbus entities to determine whether
all other entities they depend on are present (without bearing the risk of
deadlocks).
It should be
noted that Mbus entities are logical components. In particular, a process or a
thread may represent an arbitrary number of Mbus entities (which may even
communicate with one another via the Mbus).
A key concept of
the Mbus is its flexible and extensible naming and addressing scheme. Mbus
entities are identified by n-tuples. Each tuple component is represented by an
(attribute: value) peer. Currently defined attributes include conference
(conf), media (media), module type (module), application name (app), and
application instance (instance). Individual or all tuple components may be
omitted or wildcarded (*) to implement broadcast, multicast, and anycast
services. Full qualification of an address (i.e. non-wildcarded presence of all
defined components) denotes a Mbus unicast address. Furthermore, the Mbus
provides message authentication and encryption as inherent transport features.
Message authentication is needed to prevent malicious entities from taking
control or at least disturbing a user's system but also to prevent accidental
interpretation of other users' message, e.g. in case multicast transport
addresses of two users accidentally match and their transmission scopes
overlap. As the Mbus may also be used to convey personal information or keying
material (IVs, keys) between Mbus entities, the messages also need to be
encrypted to prevent other entities from eavesdropping.
A set of
user-specific resources (specified in a file, a registry, etc.) contains all
the user-specific configuration information for all Mbus entities representing
this user. The resource information includes user id, authentication/encryption
keys, multicast address/port for message exchange among others. These
facilities combine to allow the Mbus to support multiple sessions of a user per
host (including cross-session co-ordination) as well as any number of users on
the same host or link (preventing accidental cross-user interaction).
As stated above,
we can identify various component types that attach to the Mbus to form an
integrated system. The rather intuitive overview can be formalised to yield a
finer granularity of component types that is sufficient to build all kinds of
systems within the scope of the MECCANO project. The following (logical)
component types are defined:
·
(media)
engines providing the functionality necessary for telecooperation (such as
audio or video communications, shared workspace or editor, etc.);
·
control
(protocol) engines managing interactions with remote users (e.g. providing
means for call/conference set-up, floor control, mutual awareness in a
conference, etc.);
·
graphical
user interfaces (GUIs) as suitable means for a human user to access the system
functionality implemented by the (control and media) engines;
·
policy
modules that control automated system behaviour (e.g. based upon user
preferences, administrative settings, call/conference processing scripts,
etc.);
·
applets
that provide an abstraction from specific implementations of background/backend
services (such as address resolution, certificate validation, user authentication,
directory services, etc.); and
·
an
Mbus controller that may combine any number of the aforementioned modules and
add specific interpretation/processing to create a particular integrated system
type.
Particular
instantiations of these (abstract) components are implemented within MECCANO to
build the complex components to be delivered. Control protocol engines being
implemented include an H.323 engine and a SIP engine as well as a module to
communicate via ISDN lines. Media engines include at least the Robust Audio
Tool (separate engine and user interface) with an Mbus interface. Various user
interfaces for integrated terminals are likely to be developed. Finally, Mbus
controllers are designed to combine the aforementioned components to form two
important deliverables:
An Mbus
architecture framework document is in progress and will be submitted as an
internet-draft for discussion in the multiparty multimedia session control
(MMUSIC) working group of the IETF. The Mbus transport specification is essentially
complete and has two implementations, one at UCL and another at Bremen
University.
The basic Mbus
operation and bootstrap procedures have been defined, together with specific
commands for control of audio and RTP related functions. Basic call signalling
has been defined, with specific commands for H.323, SIP, and ISDN lines to
come. An internet draft, which is being written to document this, will involve
extension of the Mbus semantics to further cover basic call/gateway control,
including protocol specific extensions, floor control, dynamic control of media
session, etc.
The ITU-T Working
Group of most relevance to multimedia communications and conferencing is ITU-T
SG16, also referred to as Study Group for Multimedia. In the past they defined
a series of recommendations for multimedia conferencing called H.323. H.323 is
currently considered the standard for controlling multimedia communications in
small groups as well as for IP Telephony. The core Recommendations include
H.323 (system and procedures), H.225.0 (message formats, encodings), and H.245
(capability/media descriptions, handling of media streams). H.235 covers
security mechanisms for H.323, the H.450.x standards address Supplementary
Services for multimedia communications, and H.341 defines Management
Information Bases. Other recommendations address remote device control and text
conversation (transport and semantics in both cases).
The mechanisms of
H.323 conferencing are somewhat different to those of the Mbone described
earlier in this section. Here the basic model is that one party initiates a
communication with one other party. The extension to multi-party conferencing
comes from establishing communications through reflectors, called Multiplexing Control
Units (MCUs), which coordinate the conference and optionally replicate the data
to all the participating parties. Considerable attention to has been paid to
enabling H.323 interoperability with the pure Mbone-based applications, in
spite of the fairly fundamental differences between the conference models. The
previous ITU standards (H.320 and H.324) differed even more; they had, for
example, quite different formats at the media transport level. The foundation
for interworking was laid when the ITU adopted the RTP standards unchanged as
the basis for its H.323 media transmission.
H.323 interfaces
well to the loosely-coupled conferencing concept prevalent in the IETF through
H.332 that defines how to set up H.323 conferences, map their parameters to SAP/SDP,
and announce the conferences on the Mbone. Under the recommendations there are
considerations of how to deal with ISDN, Internet and ATM. There are also
detailed recommendations of media encodings to be supported. These include some
of the audio and video encodings supported in the Mbone conferencing. They have
long advocated the H.261 coding used by VIC and other Mbone tools; they are now
studying advanced video coding schemes (particularly including error resilience
schemes as in the 1998 revision of H.263 (also referred to as H.263+).
SG16 has
developed the T.120 series of Recommendations used for data conferencing across
arbitrary networks including the Internet. The T.120 infrastructure provides a
platform that creates a multipoint communication environment from a set of
point-to-point connections by ordering them in a tree structure and offers a
rich set of conference control functions. Also, use of native multicast
networks is supported. On top of this infrastructure, T.120 application
protocols provide means for telecollaboration through shared whiteboards, file
transfer, application sharing, and text chat. Recent developments include
support for T.120-specific security features and the design of a semantic
meeting room model (including different conferencing styles, roles, associated
privileges, etc.). Most of today's commercial shared workspaces and
particularly application sharing systems are based on the T.120 series of
Recommendations: these include Microsoft NetMeeting [netm] and Intel ProShare
[prosh].
Because of the
convergence of many of the SG16 and IETF endeavours, we have two activities
under MECCANO auspices. The first is to implement a gateway to allow ITU H.323
workstations to participate in Mbone conferences and vice-versa. Such a gateway
will be controlled, in early versions, by a message passing control bus called
Mbus. An important part of the project is to provide a sufficiently general
specification of Mbus to allow it to be used in the Mbone-H.323 gateway. In
addition, the requirements for trunking gateways at carrier class size have
been recognised by both the IETF and the ITU SG16 communities. Such trunking
gateways act as interface points to the traditional telephone network (not only
for the last mile) while the carrier infrastructure interconnecting the
gateways is entirely IP-based. This has led SG16 to embark on the design of
H.248 (formerly known as H.GCP), and the IETF community design of similar
facilities in a new IETF MEGACO Working Group. The design of H.248 is now related
to, and increasingly co-ordinated with, the IETF MEGACO WG, H.225.0 Annex G and
a variety of Annexes for more efficient communication procedures and simpler
endpoints. The functional range of H.248 / MECAGO is likely to impact the
design of the Mbus semantics layer for call signalling and control in gateways.
H.225.0, Annex G, covers inter-domain exchange of addressing information and
(potentially) other characteristics of specific devices (such as gateways)
and so may also impact the design of
the MECCANO gateway.
The second of the
MECCANO activities is to ensure the continued alignment of the two
standardisation activities - partially by our participation in both. There is
also a need to consider whether the Mbus itself should be the subject of IETF
standardisation; thus our Mbus activity is also part of the alignment
procedure.
The variety of
different network technologies, workstation capabilities and conference system
technologies preclude the adoption of a single conferencing system, at a single
speed, with homogeneous facilities. Many mechanisms have been suggested, and
some even implemented, to address system heterogeneity. At some level these may
be independent of any direct intervention inside the network. For example, if
layered coding is used, all workstations support multicast, a disadvantaged
receiver may just not subscribe to all the relevant multicast groups. However
the above constraints are too prescriptive, and the section considers what can
be done in more heterogeneous environments.
There have been
recent moves to consider Active Networks [tennen96], in which each node can do
reasonably complex packet manipulations at the IP level. We consider this much
too radical for deployment in the MECCANO project. Here we are prepared to put
in Active Components, but only at the Application level at boundaries between
technologies. This approach can be termed the use of Active Service nodes. In advanced environments, such nodes may be cloned
at will automatically and instantiated in an optimal manner throughout the
network. The requisite technology is still in the research stage and such
automated deployment will not be considered in the MECCANO architecture. We
will consider, however, several sorts of Active Service nodes.
All these
gateways have a common approach, though they have quite different purposes. The
common aspects of this approach, including the requirements, protocol
conversion, and signalling conversion needed are considered in Section 8.2. In
Sections 8.3 and 8.4 we will consider specific implementations of gateways to
provide part (AudioGate) or all (StarGate) of the functionality described in
Section 7. Here it is assumed that the IETF multicast procedures are used on
one side of the gateway, and the ITU ones operate on the other. In Sections 8.5
and 8.6 we review two tools which provide multicast to unicast conversion
within the Internet environment. The first is a simple reflector. The second,
the UCL Transcoding Gateway (UTG), is a device that is located near a specific
change in network technology. While it assumes that Mbone technology is used in
the tools on both sides of the UTG, it provides, in addition to the multicast
to unicast conversion, video and audio multiplexing and media conversion (e.g.
transcoding and packet filtering). An earlier implementation of such
functionality may be found in the mTunnel [mates] and LiveGate [livegate]
applications. It is also possible to arrange for the UTG to act as a multicast
node from the viewpoint of terminating some multicast groups and allowing
clients to subscribe to a limited range of groups.
Finally, a
component frequently deployed at administrative boundaries is a Firewall. Both
the facilities provided in such devices and the constraints that these impose
are discussed in Section 8.7. Here we suggest also mechanisms that may allow
multimedia conferencing to be deployed, even if there are firewalls in place.
The gateway architecture follows the overall
system architecture outlined in the MECCANO
Deliverable D3.1 and employs the components and control mechanisms
described in Deliverable D7.1.
Figure 9: Mbus
Architecture for Endpoint, Gateways, and Management Systems
An overview of this system architecture is
depicted in Fig. 9 with the following Mbus entities being envisioned so far:
·
Media engines providing the
functionality necessary for telecooperation (such as audio or video
communications, shared workspace or editor, etc.);
·
Control (protocol) engines managing
interactions with remote users (e.g. providing means for call/conference
set-up, floor control, mutual awareness in a conference, etc.);
·
graphical user interfaces (GUIs) as
suitable means for a human user to access the system functionality implemented
by the (control and media) engines;
·
Policy modules that control automated
system behaviour (e.g. based upon user preferences, administrative settings,
call/conference processing scripts, etc.);
·
Applets that provide an abstraction
from specific implementations of background/backend services (such as address
resolution, certificate validation, user authentication, directory services,
etc.); and
·
An Mbus controller that may combine
any number of the aforementioned modules and add specific
interpretation/processing to create a particular integrated system type.
Gateways are designed based upon the Mbus
concept. They consists of a set of
components attaching to the Mbus with one dedicated Mbus controller defining
the type of gateway and the others fulfilling well-defined pieces of the
overall functionality the gateway provides.
The building block approach and the types of components involved in the
MECCANO gateways are described in the following subsection. Subsequently, the role of the Mbus as a
transparent mechanism to control gateways is outlined as are the control Mbus
components, followed by considerations on handling of media streams in
gateways.
As all other complex systems developed in the
MECCANO project, gateways combine a set of Mbus entities to provide the desired
system functionality. Out of the
aforementioned categories, the currently developed gateways:
·
use media engines for transcoding
purposes but not for local capturing / replay of media streams;
·
use one or more control protocol engines
to interpret and encode messages of the respective protocols;
·
optionally may make use of graphical
user interface components to provide status information to an administrator and
allow the administrator to configure the gateway, intervene with ongoing calls
if necessary, etc. (however, none of the gateways currently do so);
·
do not make use of policy modules (at
this point in time);
·
employ control applets for modular
extensions to the core functions of the gateway; and
·
implement an Mbus controller that
actually implements the signaling conversion, invokes transcoding as necessary,
etc.
This subsection briefly outlines the status of
the generic Mbus entities implemented so far, while the following sections on
the respective gateways describe their Mbus controllers and how the various
generic Mbus entities fit together.
To meet the MECCANO aims, we plan to develop the
following control protocol entities:
·
A fully Mbus capable SIP engine that
implements endpoint as well as SIP proxy functionality.
·
An H.323 Mbus engine providing the
same abstract call control interface as the SIP engine.
·
A SAP/SDP engine capable of receiving
and interpreting SAP/SDP-based session announcements. It should include an
abstract Mbus interface for querying/passing information about the session
announcements. This engine will be
incorporated in the gateways of Sections 8.3 and 8.4.
·
An ISDN call control engine – again
with an Mbus interface.
·
Because the Real-Time Streaming
Protocol (RTSP) is used for remote access to media servers, we may develop an
Mbus which performs these functions
Three conversion engines will be developed in
MECCANO for use in gateways:
·
Media conversion engines between two
different encoding and/or packetisation schemes on the IP side; they may also
act as an RTP translator – for both IPv4 to IPv6 and unicast to multicast
conversion. The UCL audio tool (RAT)
already has some of this functionality for audio, and the LBL vgw for video,
but both will need considerable updating.
·
A Communication engine that will
provide an interface to an ISDN BRI thereby allowing conversion of audio
streams from the line-switched to the packet-switched environment and vice
versa.
·
A dedicated multicast to unicast
packet reflector
Only the first is really significant. The
other two largely exist, and will be convenient to deploy early in the project.
We expect more than pure audio communication
between the packet and the line-switched environments, based upon IP-capable
endpoints at both sides with a multicast-unicast gateway in the middle
providing the necessary addressing conversion. An optional transcoding gateway
can reduce audio/video quality to achieve a transmission rate suitable for the
line-switched network.
Full interoperability with H.320-based videoconferencing
systems may easily be achieved by combining the MECCANO Mbone-H.323 gateway
with an H.323-H.320 gateway. As the
latter type of gateway is now commercially available from a variety of
manufacturers, no specific efforts within MECCANO are addressing this
particular issue.
The MECCANO Audio Mbone-Telephony Gateway AudioGate should provide users on an
arbitrary telephone network (PSTN, ISDN and GSM) with access to the audio
channel of Mbone conferences. Upon
connection set-up, functions such as dynamic conference selection will be
provided. As soon as a connection to an Mbone session is
established, additional services such as user identification, muting, most
recent speaker indication, etc. may be provided.
AudioGate should provide a dial-in interface
that allows users to call a phone number and automatically be transferred into
a pre-selected Mbone session. AudioGate
will use an ISDN BRI to connect to the phone network. If a Calling Line Identification Presentation (CLIP) service is
supported by the caller and the ISDN network, the caller's phone number is
provided in the SDES NAME item to identify the person on the phone to the other
parties in the Mbone conference.
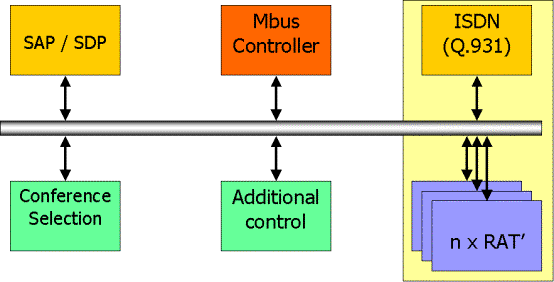
Figure 10: Mbus
architecture for AudioGate 1.0
The target architecture splits the gateway
process into several different logical components as shown in Fig. 10. These
components are expected to be implemented as separate processes, mainly using
engines discussed in Section 8.2. Only the utilisation of the same ISDN board
for control and data exchange require the ISDN call controller and the RAT
engine for a single ISDN B channel to reside within the same process, forming
two independent Mbus entities nevertheless.
The components depicted in Fig. 10 contribute to
the AudioGate functionality as follows:
·
The RAT media engine acts as a line
switching to packet-switching converter as outlined above.
·
The ISDN call controller provides a
simple interface to allow setup and teardown of calls, detection of busy and
call completion indications and provides an interface towards detection and
generation of DTMF signals as well as generation of voice clips for the ISDN
side.
·
The SAP/SDP module receives session
descriptions from the announcement channel(s) and extracts the information
relevant for identifying and joining Mbone conferences.
·
The conference selection module
receives session descriptions from the SAP/SDP module and turns them into a
choice list assigning each conference a numeric identifier by which the
conference to be joined can be picked (via DTMF). The conference selection module also implements a filtering
mechanism (to be configured e.g. via a simple resource file) to limit the
access to a certain subset of conferences.
·
The Mbus entity marked additional control is intended to
provide an extensible set of additional features, largely based upon DTMF
selection by the telephone user. Such
services may include muting/un-muting the telephony user, changing the volume,
among others.
·
Finally, the Mbus controller for the AudioGate
glues all these entities together by accepting input from the various other
Mbus entities and forwarding them appropriately. For example, to direct DTMF
received from the user to the conference selection module while in the set-up
phase and directing them to the additional control module when already joined
to a conference.
AudioGate will be developed in several
phases. The initial phase will focus on
implementing, testing, and optionally enhancing the core components with less
focus on the overall Mbus architecture.
The MECCANO call signalling and media
transcoding gateway StarGate is supposed to provide connectivity between
different kinds of endpoints interconnected through different types of networks
(hence the name *Gate). This is expected to include in particular:
·
Conversion between the three most
important call signalling protocols (H.323, SIP, and ISDN) including media
stream conversion if necessary;
·
Actively accessing Mbone sessions from
H.323 endpoints; and
·
Inviting H.323 endpoints into Mbone
sessions for audio and optional video communications.
The architecture of StarGate also allows us to
easily extend the number of supported call signaling protocols. In addition, if
feasible from the standardisation point of view (i.e. the necessary
specification are complete and stable), security aspects will be incorporated
into the StarGate implementation.
StarGate is conceptually built upon the same
general Mbus architecture as AudioGate, with largely different Mbus entities
and different interactions between them, of course. A conceptual outline of a possible StarGate implementation is
shown in Fig. 11.
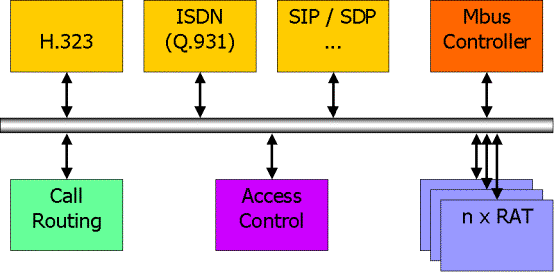
Figure 11: Outline
of the MECCANO StarGate
The various components perform the following
tasks:
·
The H.323, SIP/SDP, and ISDN modules
implement call signalling and (as far as applicable) conference control
functions for the respective protocol suite.
·
An Mbus RAT entity is instantiated
whenever transcoding (e.g. for interconnection to the telephone network) is
required.
·
The Call Routing module provides
address and endpoint reachability resolution and, in particular, decides which
protocol to route an incoming call across.
·
The access control module is used to
verify that incoming calls are authorised to be completed according to the reachability
decision taken by the Call Routing module (e.g. whether an IP-side caller is
allowed to call a long-distance number via the telephone network).
·
Finally, the Mbus controller again
provides the necessary glue between all the modules forwarding call messages
back and forth, keeping per call and resource utilisation state, etc. In particular, it knows which control
protocol entities are present and is optionally capable to translate
non-standard Mbus call control messages between the various protocols and
instantiate / configure the rat media engine(s) accordingly.
·
Further Mbus entities (control applets
as well as policy modules) may be introduced to provide additional
functionality such as value added services based upon DTMF tones or similar
signalling from the IP side.
All three of the
aforementioned control protocol entities share a core set of Mbus messages to
set up, tear down, and monitor progress of a call. In addition, each entity supports protocol-specific Mbus
extensions that may not be (easily) mapped to other control protocols. The Mbus controller is expected to
understand all these Mbus commands, route incoming messages, and optionally
perform translation between different protocols.
Call control messages are intended for
interaction with call control and invitation protocols such as H.323 and SIP.
They are designed to constitute the union of the call control messaging needed
by endpoints, gateways, proxies, multi-point controllers, and gatekeepers. This
allows the use of the Message Bus to act as gluing mechanism to create any type
of system from roughly the same building blocks.
Mbus call control messages are based on a common
basic message set defined in the following that will be supported by any kind
of call control protocol entity. The basic message set may be augmented by
protocol-specific extensions required for protocol specific interactions
between a local controller and/or local applications on one side and the
respective protocol engine on the other. While the basic Call Control commands
have been worked through, these will be described in futureWP6 Deliverables.
They must be mapped to H.323, SIP, and ISDN-specific messages.
A possible future extension for MECCANO is an
Mbus command set for the Real-Time Streaming Protocol (RTSP) extensions. However, this is left for further study.
In the current IP multicast
model, it is often desirable, for several reasons, to transmit multicast
traffic to selected destinations using unicast transport. One reason is that
not all IP hosts are connected to the Mbone, for both technical and
administrative reasons. Another is that, as the virtual private networks become
more widespread, particular care must be taken to not shuffle the multicast
traffic originating from them and from the regular Mbone; otherwise multicast
routing may be affected (routing loops, undesired routes and traffic).
Several multicast-to-unicast
reflector solutions (called also replicators, transmitters or gateways) are
implemented today. These are either based on specific, custom-designed
protocols and software [livegate], or are far too difficult for an
inexperienced user to install and use [rtptrans]. A more complex functionality
is implemented in UTG (see Section 8.6).
While implementing the
reflector engine is rather simple, controlling it in a simple manner is far
from trivial. We prefer to set only two requirements for the reflector control
interface:
1) using the
reflector to stream media must be as
simple as browsing the Web
2) there should be
no assumptions on the users’ capabilities but the ability to use a Web-browser
and run an installer application.
We have chosen to control
the reflector functionality using Real-Time Streaming Protocol [schu98]. RTSP
simplifies Web-integration and includes the necessary streaming control
functionality for both unicast and multicast transport.
The
multicast-unicast reflector is build around its principal part, the reflector
engine and control server (or simply Reflector,
residing on Host 4 in Fig. 10). This entity joins the multicast groups and maps
the traffic to/from selected unicast hosts.
The reflector is
controlled by an RTSP server. The RTSP server includes the reflector control
module, which is used whenever a multicast session needs to be delivered using
unicast transport (this task is easy to specify using the standard RTSP
syntax).
On the client
side, a separate control application, StreamerApp, is used in addition to the
standard media tools and Web client. The Web client is configured so that
StreamerApp is the helper application for .rtsp
file extension. StreamerApp has a simple control interface, and includes RTSP
client functionality. It also starts (and terminates) media tools.
The HTTP server
shows the multicast session announcement information for active and future
multicast sessions. The Announcement collector, listening to the well-known SDR
announcement address/port, supplies this information. The same information is
sent to the RTSP server.
In Fig. 12, only
Host 4 must reside on a multicast-enabled network. All other hosts may be on
non-multicast networks. Nevertheless, Host 1 has full access to all multicast
sessions known to Host 4.
Figure 12: Reflector architecture
Co-hosting the
announcement collector with the reflector engine is desirable due to the
multicast group scope (sessions seen
on different LANs may vary). Otherwise, the various components can be co-hosted
as needed (e.g. HTTP server, RTSP server and the reflector can be executed on a
computer equipped with a DBS satellite receiver).
The user reads the
information about the current multicast sessions using his Web browser.
Clicking at any of the links returns an RTSP-file (e.g. seminar.rtsp), containing only one line: URL for the session
description (rtsp://rtsp.ifi.uio.no/seminar.sdp).
The Web client is configured so that it starts StreamerApp as the helper
application for the .rtsp file
extension. StreamerApp connects to the RTSP-server specified by the URL, and
demands the description of seminar.sdp.
This file describes a multicast session, but StreamerApp demands it delivered
by unicast transport, using a standard RTSP set-up call. The RTSP server
satisfies this demand by instructing the reflector engine to join the new
multicast group(s) and to replicate the RTP traffic to specified unicast ports
on Host 1. After the set-up request is acknowledged, StreamerApp starts the
media tools.
The UCL Transcoding Gateway (UTG) is another
approach to providing access to multicast conferences for hosts with only
unicast connectivity. In addition, it provides limited transcoding and mixing
functions, primarily for audio.
The initial version of the UTG was developed as
part of the MERCI project before the Mbus concept was fully developed. We
delivered an enhanced version of this (UTG v1.2) in MECCANO Deliverable D4.1.
As part of MECCANO we plan to extend the UTG to fully embrace the Mbus
architecture in a similar manner to the StarGate system, although the
components used are somewhat different. The functionality is more powerful than
that of Section 8.5, though the control concepts may converge eventually. A
conceptual outline of the UTG system is illustrated in Fig. 13.

Figure 13: Conceptual
outline of the UTG system
The components in the UTG architecture are
expected to perform the following tasks:
·
The RTSP controller module will
provide the control interface to the unicast end-system.
·
The access control module is used to
verify that requests for transcoding and gatewaying are from authorised users.
·
One or more media engines are
instantiated to perform transcoding and gatewaying.
·
Finally, the Mbus controller provides
the necessary glue between all the other modules.
A number of the components necessary for the UTG
already exist. In particular, the media engines are well developed although
some need updating to match the current Mbus specification, rather than earlier
ad-hoc control protocols. The access control module is expected to be somewhat
similar in concept to that employed in the StarGate system.
The RTSP controller is a new piece of the UTG
architecture, and is intended as a replacement for the current control
protocol. We expect to develop this in two stages:
1) by integrating an Mbus interface into the current UTG control
module, reusing as many of the call control commands defined in Section 8.2 of
this deliverable as possible; and
2) by converting the current control protocol to use RTSP whilst
retaining the control interface.
Most commercial organisations, and increasingly
even universities, use firewalls to constrain Internet packets passing between
the outside and their internal networks. In a firewall-less environment,
network security relies totally on host security. A firewall approach provides
numerous advantages to sites by helping to increase overall host security. It
can filter inherently insecure services, enhance privacy of certain sites by
blocking innocuous information that would be useful to an attacker, like IP
address or user name. It also provides the ability to control accesses to site
systems, and hence the means for implementing and enforcing a network access
policy. The firewall can log accesses, provide valuable statistics about
network usage and details on whether the firewall and network are being probed
or attacked.
Normally firewalls do not allow the free flow of
the UDP packets, which are fundamental to the Mbone. For, blocking them is the
only effective way to block access to dangerous RPC-based services. In MECCANO
we are trying to develop mechanisms which will be considered sufficiently
secure to allow tool deployment inside organisations protected by firewalls. A
multicast security policy consists of specifying the set of allowed multicast
groups and UDP ports that are candidates to be relayed across the firewall.
There are two different ways to support such a policy: an explicit dynamic configuration or an implicit dynamic configuration.
In the case of an implicit dynamic configuration, the set of candidate groups/ports
could be determined implicitly, based upon the contents of SAP announcements or
other SDP descriptions. A watcher
process reads and interprets these announcements in order to update dynamically
the filtering rules of the firewall. In the case of an explicit dynamic configuration, the set of candidate groups/ports
could be set dynamically, based upon an explicit request from an internal
trusted client. This solution is similar to a proxy architecture. An insider
talks to a UDP proxy server and asks it to relay a multicast session. If this
request is approved, the proxy server joins the specified multicast group and
relay the data to and from the client.
Of course, this architecture could be adapted to
allow the use of multicast on the Intranet or to make easier the practical
application of such a solution. The UDP proxy server must indeed be set on the
firewall itself. But some organisations are reluctant to modify their firewall.
In that case, a tunnelling approach could be considered. A multicast-unicast
relay is situated outside the firewall to an organisation; only unicast
connections can be initiated from the inside of the firewall through the
protected area. Inside the protected area, another unicast-multicast relay is situated.
If users inside the protected area wish to join a conference, they launch their
applications internally. The relay inside the protected area then opens a
unicast tunnel to the relay outside; it can then perform any necessary checks
on traffic passing between the two areas.
The implicit
and explicit approaches enhance
security by dynamically defining the set of allowed sessions. They can both
provide additional services like user authentication and logging facilities.
However, the proxy solution seems to be a better option since it has more
efficient logging facilities and more control over the permitted port numbers.
Moreover, at the moment, it is a fundamental tenet of current security thinking
by most organisations, that Mbone traffic should be authorised only from inside
the protected area. For this reason, we are exploring the proxy solution or its
adaptations.
Some important issues still remain with such a
proxy mechanism. In particular, it does not scale well. We will explore how
severe a drain on resources this mechanism is in reality, and whether it is
satisfactory to all the partner organisations.
There is a
temptation to believe that multicast is inherently less private than unicast
communication since the traffic visits so many more places in the network. In fact, this is not the case except with
broadcast and prune-type multicast routing protocols [deer88-2]. However, IP
multicast does make it simple for a host to anonymously join a multicast group
and receive traffic destined for that group without the knowledge of the other
senders and receivers. If the
application requirement (conference policy) is to communicate between some
defined set of users, then strict privacy can only be enforced in any case
through adequate end-to-end encryption.
RTP specifies a
standard way to encrypt RTP and RTCP packets using symmetric encryption schemes
such as DES [des]. It also specifies a standard mechanism to
manipulate plain text keys using MD5 [riv92], so that the resulting bit string
can be used as an encryption key. Similar techniques can be used for encrypting
the contents of the non-AV portions of the conferences. Most of our early work
has been done with DES because of the prevalence of the implementations; later
we will move to more secure encryption algorithms. The symmetric encryption
algorithm used has only pragmatic, not architectural, significance. We realise
that DES is now denigrated in the IETF community - being relegated to historical status. In this architectural
note we will normally use the words DES for a fairly conventional symmetric
encryption algorithm more as a short-hand.
There are
mechanisms defined in the IETF for standard secure operations [gup99]. These
are not yet defined fully for multicast operation; in particular, the
key-exchange mechanisms are not yet developed. There will be some discussion of
mechanisms for multicast key distribution given below; however, we have not yet
decided how IPSEC would be used in these applications, and it is not considered
further in this report. The use of IPSEC is part of other research projects
that the MECCANO participants (in particular UCL) are doing with other funding
bodies. The results will not be reflected, however, into the MECCANO
Deliverables during the remaining life of MECCANO.
Because the use
of plain text pass-phrases can be used to derive symmetric encryption keys, one
can use simple out-of-band mechanisms such as any privacy-enhanced mail e.g.
[pgp] or S-MIME for encryption key exchange. It is also possible to integrate
the key-exchange mechanism at least partially into the session announcements
and invitations. Each of these methods is considered below.
There is
currently considerable discussion of whether Session Announcements are an
appropriate mechanism for announcing limited sessions - and thus whether there
is a place for encrypted Session Announcements at all. Already, with most
sessions still unencrypted, the bandwidth taken up with Session Announcements
is a large proportion of the bandwidth assigned to announcements, which has
been deliberately limited. Hence there is typically a ten minute gap between
announcements of a session. Another concern is that one of the functions of
Session Announcements is to avoid conflicts in the use of multicast addresses;
this avoidance is impractical if the whole announcement is encrypted; if the
multicast address and time is sent in the Clear, too much information is
released. The first concern could be addressed by using Session Announcement
cache proxies; the second by separating out the address allocation
functionality from the rest of the announcement mechanism. Both questions are
still being discussed in the IETF. In the meantime, the standardisation of
encrypted session announcements is being hampered; some of the mechanisms
considered here have not been ratified by the IETF.
As mentioned in
Section 6.2.1, if the media or shared application tools send their data in the
clear, then it is easy for anybody knowing the time and multicast address of a
session to participate. Moreover, since the RTCP responses could be suppressed,
the participation may be unnoticed by the other participants. For this reason,
private conferences will need to have the data streams encrypted. Because of the
processing load arising from encryption, it is customary to always encrypt the
streams with symmetric algorithms. Typically one uses DES [des], though it
would be possible to use triple-DES [tdes] or IDEA [lai92] or any other such
algorithm if desired. In view of the current move in the IETF to abandon DES,
because of the ease of cracking it, we will presumably move over to triple-DES
or IDEA here too - though this is a pragmatic detail, not something of
architectural significance.
A subset of the
tools used in MECCANO have had the capability for encryption added; the subset
is large enough that most of functionality for encrypted conferencing is
available. These tools are currently VIC, RAT, VAT, WB, WBD and NTE.
As mentioned in
Section 6.2.1, the announcement and invitation to conference sessions is
critically dependent on the passing the Session Description (SDP) [han98] to
the authorised invitees. This information can be passed by many technologies -
both in-band and out-of-band.
There are three
main reasons for providing authentication in announcements and invitations. One
is that if one intends to provide billing depending on the announcement itself,
then some form of authentication is essential. The second is that one may wish
to be sure that the conference has indeed been called by someone who is
authorised to do so. A third is that there are also mechanisms for modifying
Session Announcements; a simple Denial-of-Service attack is to modify the announced
time or location with unauthenticated announcements.
It is essential
that any information about the Session Description encryption be passed
securely between the persons authorised to participate.
Key distribution is
closely tied to authentication.
Conference or session Description keys can be securely distributed using
public-key cryptography on a one-to-one basis (by email, a directory service,
or by an explicit conference set-up mechanism). However the security is only as
good as the certification mechanism used to certify that a key given by a user
is the correct public key for that user.
Such certification mechanisms [x509] are, however, not specific to
conferencing, and in the conferencing portions of the IETF (the MMUSIC group),
a strong preference for using PGP certificates [pgp] has been expressed.
Session keys can
be distributed using encrypted session descriptions carried in SIP session
invitations, in encrypted session announcements, or stored in secured
depositories with access control. None
of these mechanisms provide for changing keys during a session as might be
required in some tightly coupled sessions, but they are probably sufficient for
most usage in the context of lightweight sessions.
Even without
privacy requirements in the conference policy, strong authentication of a user
is required if making a network reservation results in usage based billing.
These considerations are orthogonal to the announcement of sessions; they are
relevant, however, to the mechanisms adopted on joining sessions.
Private sessions
can be announced in many ways; and we will be using several in the MECCANO
project. All are based on using encrypted sessions, and providing the Session
Description (SD), complete with its Session Encryption Key(s) (SEK), in a
secure way to all authorised participants. While each media stream may use a
different SEK, it is important that the same SD can be used irrespective of the
manner it is transferred. This allows the facility that launches the encrypted
media tools to be oblivious of how the SD came to the recipient.
It is fundamental
to our architecture that anybody participating in secure conferencing must have
a Public Key Certificate. This is used to send some shared secret between the
conference organiser and the conferees. For small-scale, ad-hoc conferences, it
is possible merely to send the SD to all the conferees with PGP or S-MIME mail,
merely encrypting the SD with the Public Key of each recipient. An alternative
is to use SIP [sip], with its security features, to invite specific people to a
conference.
A third way of
distributing the Session Directories securely, is to put them in a depository
like a web page or an X.500 Directory. There can be access control to ensure
that only persons authorised to participate can retrieve the Session
Description. The access control problem then reduces to the management of the
access control lists in the relevant depository. If the depository is a secured
Web Server, for example, one can ensure that access is only possible in an
encrypted and authenticated session; this ensures that eavesdroppers could not
tap into the SD information while it is being retrieved,
A fourth way of distributing
the Session Directories securely is to encrypt them with a symmetric encryption
mechanism such as DES [des], Triple DES [tdes] or IDEA [lai92], using a Session
Announcement Encryption Key (SAEK), and to send them out in the encrypted form
by SAP. There are then at least two mechanisms that can be used with SAP. One
is distribute previously a number of symmetric SAEKs in advance to the
authorised participants, for instance by secure e-mail. These keys could be
distributed with an index number. The SAP announcement could then carry that
index number and the relevant key could be used to decrypt the SAP
announcement. Alternately, one could choose not to use an index number; the
recipients would then need to try to decrypt each incoming session announcement using one after another of the
SAEKs in his/her cache. This need be done only the first time the encrypted
announcement is transmitted, since there is a unique hash associated with each
announcement, which tells the recipient if they have seen the announcement
before.
Yet another way
of sending encrypted announcements uses Public Key Cryptography (PKC) in an
unusual manner. The SAEK can then be encrypted with one of a PKC key pair (say
the Public one, and this message is
pre-pended to the transmitted announcement. The Private one of the PKC key pair is distributed only the authorised
participants; thus only they are able to decrypt the pre-pended message – and
hence derive the SAEK. Even here there are several variants. In one both the private and the public key pair are distributed to each authorised participant. In
this case any one of them can announce private conferences. Another variant
maintains more of the spirit of PKC, in that it allows only one person to
announce conferences; thus only the Public
key is distributed. This mechanism is particularly appropriate if one wishes to
ensure that broadcast events are indeed announced only to authorised persons.
The use of
public-key or strong symmetric cryptography for this purpose has not yet been
standardised, because of disagreements on which technology is most suitable.
The standardisation of these mechanisms will clearly accelerate the use of
secure conferencing or commercial broadcasting. The considerations include the
frequency of change of the groups, the nature of the events to be announced,
the amount of infrastructure one assumes amongst potential participants, and
which is the easiest to implement - in view of the security toolkits now
available. For this reason the IETF does not prescribe which method is to be
used.
All these
mechanisms require that there be some mechanism for managing groups securely.
Either shared secrets must be sent to groups, or access control lists must be
maintained for groups. Specific infrastructures for group management are being
studied in the ICECAR project. A companion architecture document for ICECAR
[icesecarc], goes into further detail on this issue.
The ability to archive
multimedia data from conferences and to introduce stored data into conferences
are requirements in many multimedia conferencing applications.
Recording a
multimedia session enables anyone who could not originally participate to
replay it and find out the content of the discussion or seminar. Additionally,
a participant in an on-going conference may play back a pre-recorded clip in
order to illustrate a point. Multimedia servers with multicast capabilities
along with recording, playback and editing facilities must be an integral part
of the emerging multimedia computing infrastructure.
The five
functions of recording, storage, editing, announcement and playback are quite
separate. They may use quite different equipment and techniques - though there
must be an integrating software system to ensure that the system is easily
usable. It is both acceptable, and in the future probably normal, that there
will be diverse systems for recording, with yet others for playback. There will
often be economy of scale in the set-up of large play-back centres. Because of
performance problems in communications subnets, it may not even be feasible to
have all recording so centralised. This section describes some of the
architectural considerations in such systems.
The whole
question of Recording and Playback of multimedia data is a large subject; its
current usage dwarfs that of conferencing by several orders of magnitude. In
this section we will consider only those aspects of the subject applicable
directly to multicast, multimedia, conferencing.
A multimedia
conferencing session on the Mbone may consist of multi-way real-time audio and
video, a presentation tool for figures/slides, and the so-called ‘shared
workspace’ media (e.g. an interactive drawing tool and an interactive text
editor). For the purpose of this section, it is important to consider the
provision of both storage and retrieval of accurate representations of the
conference. Because the multimedia conferencing that is the subject of this
report is based on IP multicast, a source can send data to multiple receivers,
without the need to address each receiver individually
The requirements
on a recorder are the following:
·
Recording from the Mbone The ability to record
multicast data over the Mbone is vital. During a videoconference, the data can
be transmitted based on a variety of protocols (e.g. SRM, RTP) which the record
mechanism must be able to handle; it must be possible to record data from all
conference participants unless the user prefers otherwise. It would be
permissible to use recording caches.
·
Error Recovery If there are error recovery
techniques used in the transmission (e.g. redundancy in the audio stream
[redenc] as used in the ‘rat’ audio tool), the recorder, or recording caches,
should utilise these prior to storage of the data.
·
Data Formatting It is best to store cache
data in its original transmitted form, but the reconstructed data in a storage
format, which may well be different from the transmission format. The storage
format will normally include timing and stream information to allow faithful
play-out of the stored data.
·
Flexible data storage The amount of
data involved can be very large and thus require access to a large data
repository. Thus, the recorder must have access to a large archive space where
people can store data; this has the additional effect of keeping all recordings
in a single location (which can be transparent to the users) making them
readily accessible.
·
Confidential storage Notwithstanding
the access control mentioned above, it may be desirable to store the data in
encrypted form. Often the encryption algorithms used in transmission may be
inappropriate for storage. In addition, we have already mentioned the need to
correct and format data for storage. As a result, it will normally be desirable
to make the recorder a trusted member of any encrypted conference. This allows
the recorder to decrypt the received streams, apply the relevant data
correction, re-format the data, and add the appropriate annotation. It is still
possible to re-encrypt the data prior to storage, and to store the new
encryption algorithm ID and key under a specially access-protected portion of
the Server.
As stated in
Section 4.1.1, applications transmitting continuous media data (i.e. real-time
audio and video) use the RTP (real-time transport) protocol [schu96-2] on top
of UDP. Use of RTP/RTCP does not guarantee the quality of service; neither is
the delivery guaranteed nor may the delay be bounded. The interactive use of
continuous media makes the application intolerant of long delays exceeding a
few hundred milliseconds. A recording is not so intolerant; it can tolerate
long delays - provided only that the time of the launching of the original
packets is known. Some whiteboards also send their streams with RTP and may
even permit synchronising them with the continuous media streams [bach]. The
AOFwb described in Section 5 is an example of such a stream.
Many multicast
tools require reliable data delivery. One mechanism is to use a form of
reliable multicast [floy95] (again on top of UDP) to guarantee that the data
will eventually reach all participants. In some forms the sender is informed,
and retransmits lost packets to individual receivers. In other forms of
reliable multicast, recipients detecting loss send out a general request for
repair; the nearest up-stream source retransmits the missing packets. Some
tools are not real time; they ensure that data is sent eventually; examples
include presentation material that is pre-sent to be cached locally. Other
tools are near real-time, such as shared workspace. Here, both the speed of
response and reliable delivery are required, but some speed of response is
sacrificed for more reliable delivery. It is possible for the Recorder to wait
rather longer than a real-time conference participant, but the problem of
achieving an accurate record of data transactions is essentially the same.
A record can be
captured merely by making one or more recording workstations a member of the
conference; each will then receive the data transmitted from each of the
sources. If there is any loss in the network, recording workstations at
different locations may gather different view of the conference. One way of
improving the quality of recordings over real-time conference participants, is
to provide recording caches at strategic parts of the network. These act as
multiple recorders, and may participate in any of the error correction schemes
used by real-time participants - e.g. FEC with some corrections by redundancy,
or reliable multicast with error recovery from neighbours. In addition, the
caches will number received packets, so each knows which ones are still
missing.
Any recorder may
then augment its record by using a reliable mechanism (multicast or unicast) to
obtain missing packets from other caches. This correction can occur during the
conference, or in a subsequent repair phase. The advantage of this technique is
that one can overcome losses, at least improve over temporary catastrophic
performance losses in the network, or
even recover from temporary network partition, at a later stage. There remains
questions of how to optimise the number and location of such caches, and what
mechanisms of repair to use - e.g. unicast or multicast methods. Further
details on this technique are available in [lam99].
One important
enhancement to multimedia conferencing is the use of data encryption mechanisms
[kirstein99] to provide privacy. Only participants that are in possession of a
valid decryption key can decipher the media streams. The complexity raised by
security considerations is discussed in Section 9. If the encryption is applied
to all the data, including sequence numbering, then the use of data recovery
techniques may be impeded both during the production of any data caches, and in
subsequent repair. If one deliberately limits the amount of packet header data
that is encrypted, e.g. by keeping sequence numbers in the clear, then there
will be some potential security compromise. The seriousness, and mechanisms for
limiting, such compromise must be evaluated in specific instances - related to
the relevant security policies.
The formats used
for data transmission were designed with specific considerations in mind. For
example the RTP/RTCP format allows the receivers to tell when data packets are
missing. This can be used in several ways. For example, if there is redundancy
in the real-time data (e.g. the low quality audio from an earlier audio packet
as used in RAT [redenc]), an attempt can be made to patch up the stream. At the
same time an RTCP control packet, informing of the loss can be generated; the sender
may use this information to reduce the rate of traffic transmission. For
reliable multicast traffic, requests for retransmission can be generated by the
receiver. If an up-stream unit re-transmits the data, a repaired stream will be
generated; if not, it may be possible, or even necessary to discard some of the
data.
By using the
properties of the tools, it will often be possible to reconstruct a reasonable
replica of the information originally transmitted. If the transmitted form of
data is stored in caches and later re-transmitted other errors may be
corrected. If the data is stored permanently in exactly the same way as it was
received in a single cache, it may be difficult to reconstruct later the data
(because of changes in the tools, for example), and the characteristics of the
re-transmitted data may not be optimal. For example, the later request for
transmission of the stored data may be over a network with different error
characteristics or speeds, so that different transmission formats may be optimal.
Most of the
current Mbone-based recorders just store the RTP packets; this eases the
problems of storage and replay - but may have both performance problems, and
lead to sub-optimal solutions. There are few Standards yet for the storage
formats; most of the companies providing commercial servers (e.g. Oracle [ovs],
Cisco [iptv], Microsoft [nshow], Real Networks [realn]) have their own formats.
There has been little activity on standardising these - except the ASF format
of Microsoft [asf].
Even in the
simplest multimedia conferencing scenario, a record/playback tool may prove to
be useful. Some example uses of a Mbone recorder/player are given below. Based
on its potential uses and the characteristics of existing media tools, the requirements
that a Mbone recorder/player must fulfil are then determined.
a)
Introducing a pre-recorded clip in an on-going conference in order to
emphasise a point (Examples are pieces of operations in medical training,
foreign scenes for language teaching, and the results of flight simulations for
aerospace conferences).
b)
Replay of conferences recorded previously (Examples are because of an
inconvenient time for people who missed, a permanent record of important
seminars, and the complete background for a later conference where some event
is being reviewed).
·
Playing to the Mbone or a single user The playback
mechanism must be capable of playing back the streams (providing the option to
play all or just some of them) from an archived conference. This playback can
be directly to the user requesting it (i.e. unicast) or to another multicast
group on the Mbone.
·
Random access It is deemed necessary that
‘random access’, ‘fast forward’ and ‘rewind’ facilities be provided in the
player. These are needed both for the media streams and for the reliable data.
·
Data access control The player must be able to
require strong authentication to allow access to particular recordings. This
requires the ability to handle encrypted data. Several mechanisms can be used
for keeping data confidential. Clearly there should be access control with
Access Control Lists and/or password control on access (with strong
authentication to preclude replay attacks).
·
Data formatting The player must be able to
reformat the steams in a format appropriate to the re-transmission medium. This
may be either unicast or multicast, and use the appropriate packaging like RTP,
Reliable Scaleable multicast, etc. Additionally, the facilities to play back
media streams other than those of pre-recorded conferences (e.g. digitised MPEG
[mpeg] or AVI [avi] streams) must also be provided.
·
Data browsing Most recording engines will
quickly store a sizeable collection of recordings. There must be mechanisms for
cataloguing the data. There must also be mehanisms to allow authorised parties
to browse the catalogue, and to start up particular playbacks to specific
multicast groups.
·
Remote Control The system should allow
users to interact with the record/playback mechanism remotely; a locally
controlled system is too inflexible. The remote control mechanism should
allow interactive set-up and control of recordings and playbacks.
·
Navigation and editing The system
should provide editing facilities to enable users to create their own material
from already archived streams.
·
Annotation tracks For many purposes it is
important to be able to navigate through recordings - e.g. for editing. An
annotation track can be a very useful adjunct to aid such navigation and
editing.
·
Large-scale access For some purposes, it may be
desirable to have extremely large and highly available libraries of recordings.
It is relatively
easy to introduce the data from a multimedia recording of a whole conference.
It is necessary only to make the recording workstation a member of the
multicast conference, and it may distribute specific components of the stored
data to all the conferees. During the retrieval phase, the relaxation on
latency times no longer apply. The
impact of network performance on the quality of data perceived by subsequent
conference participants is the same for recorded as for real-time data. However
the mechanisms used at the replay stage may be optimised to reflect the network
topology and performance at that time rather than at the recording time. Thus,
for example, the recorded data may be stored in a way that has removed
redundancy; further redundancy may be added during the subsequent retrieval
stage in a way that is optimised for the retrieval network and workstations.
Several multimedia server
systems have been developed previously. Some systems have the Mbone as their
application area. Their facilities range from simple command line tools
handling a single stream, to systems for recording and playback of a whole
multimedia session. Others aim to work over the Internet or high speed
intranets.
Irrespective of their
application area, all systems have a generally common architecture. The generic
schematic of a Recorder/Player system is shown in Fig. 14.
The
different systems have different characteristics with respect to Fig.14. Many
of the commercial Video-on-Demand systems such as IP/TV [iptv] from Cisco, Real
Networks [realn] and Net-Show [nshow] from Microsoft, and the Oracle Video
Server [ovs], concentrate only on the Player section. They usually have
proprietary data formats in the data archive. In most cases they play through
an Intranet, without multicast, to single players. In some the Client and Server
are based on WWW clients and servers, with specific plug-ins for the media
tools. These can operate over multicast only with a multicast proxy, since HTTP
is defined only for unicast. However,
many of these systems are designed for high performance, multiple sessions.
They pay great attention to optimal use of disc storage - often by striping the
data across the discs in the archive.
Figure 14 The
generic architecture of a multimedia server system
For the rest of this paper
we will consider only those recorder/players which work with multicast over the
Mbone. These normally use the generic architecture of Fig. 14. At present all
of them use the available Mbone conferencing tools in the client role - though
there are some variants.
There are
considerable variations on the client/server dialogue. While there is an
increasing tendency to have this modelled on the WWW, this is not universal.
Many of the current systems have ad hoc control
of the Server from the client, but there has now been a specification of the
Real-Time Streaming Protocol (RTSP) to specify this control. RTSP has the more
general aim of controlling all classes of recorders and players, so that it is
more general than may be needed for this application. Many of the players and
recorders currently being developed use RTSP. There is insufficient experience
whether enough common features are used that the clients from one system can
interwork with the Servers from another from the control viewpoint.
Many of the
server systems allow the clients to browse the archives using a WWW interface.
Again, the way that the information on stored sessions is shown on the client
is still somewhat different in the various implementations. This difference is
not important for interoperability.
Some of the
existing standards used during multimedia conferencing (as described in Section
3.1) can be used during recording and playback of sessions. The information in
a Session Description is important for setting up the recorder and in any case
may need to be stored in with the recorded streams. The SDP information used
for play-back may be different from that used on recording. For example
different redundancy schemes may be used on play-back, and there may even have
been different encoding between the scheme used for transmission prior to
recording, and that used for playback. At present, many of the VoD players do
not use SDP, but most of those used in conferencing systems do.
There are
implementations of SAP (e.g. sdr [sdr]) which allow for a Record option; this
could start a specific recorder when the conference is started. Additionally,
the Session Invitation Protocol can be used to invite a player to an on-going
session. It is therefore possible to arrange for the introduction of recorded
clips into the conference. SIP has not yet been used to invite players but we
expect this to happen shortly.
The recorders may
operate in several ways. The simplest is to store the media packets as they
arrive, usually together with time-stamps. This is a possible approach; in fact
many of the current implementations use it. However, as discussed in Section
10.2.1, it is often better to store the media in a more suitable storage
format. This requires an equivalent of the original media tool to be incorporated
with the Recorder. In that case, it is also possible for the recorder to
undertake the stream repair, so that the information stored on the Server has
the same quality as that in real-time players located at the same site. The
information from the SDP relevant to the conference is used to set the correct
parameters in the media tools co-located with the Recorder.
The players must
operate in an analogous way to the recorder. If the native media packets are
stored, then the player can play these back - using the stored time-stamps to
pace the output. If QoS parameters can be set in the network, these can be used
in the play-out. If a different storage format has been used for the media
streams, then the player must also incorporate format converters and media
tools.
The UCL development of MMCR
[lam99] is typical of such recorder/players. MMCR is a system specifically
designed for recording and playing back multicast multimedia conferences over
the Mbone. It has a client - server architecture (as shown in Fig. 15) and
consists of the client User Interface and the server (which incorporates the
playback, recording and browsing mechanisms); logical component independence
simplifies development and component replication.

Figure 15 The
overall architecture of the MMCR
All server
components have access to the database archive (see Fig. 15) to store/retrieve
recordings and information about them. Much research has considered ways of
providing efficient storage/access mechanisms for Video On Demand (VOD)
systems, which require high bandwidth delivery. However, the simple disk model
used here is adequate considering the current bandwidth limitations on the Mbone
and a Redundant Array of Independent Disks (RAID) can be integrated in the
system as an enhancement, if necessary.
The server acts
as the single point of contact for recording, browsing and playback. Most of
the existing implementations have a similar architecture. They consist of
independent components; a server manager, the player, the recorder and the
browser; some of these components may be missing in specific implementations.
The server
manager controls the whole service; it handles the establishment of connections
with the clients. It has a separate, independent interface for each task and
more interfaces can be added when required (e.g. an editing interface).
Depending upon the type of service requested by the client, the server manager
starts one of the recording, browsing or playback mechanisms. Once the
mechanism required has started, the remote client communicates directly with
that mechanism. Each mechanism has its own text-based control protocol.
To record the media streams
the recorder need not be an active part of the conference; it ‘listens’ to the
specified multicast groups and collects the data. Each stream is stored
separately. In the case of RTP media, the RTCP messages transmitted are stored
along with the data packets.
Information about each
recorded media (e.g. type, name) and each source (e.g. data location) is saved
in header files. This information is either provided by the user or it is
included in the Session Description of the conference. It is then possible to
catalogue and index the descriptions for subsequent retrieval. This indexing
may be in text form; some current research projects [sahouria] are attempting
to use non-textual forms of indexing to allow more sophisticated retrieval.
A listing of
conferences a server has stored in its archive can be obtained through the
browsing mechanism. A title keyword search facility is also available to help
identify titles of interest.
Further details
about a particular conference can also be obtained to assist a user in deciding
which conference to play back. These details include the conference’s title and
description and the media that constitute the session. Additional information
on each media includes the data type (i.e. RTP, wb etc) and the names of the
users (where available) to help users select only the required data streams.
The real advantage of storing data on a per source basis is that users
can playback only the streams they are actually interested in - ignoring the
rest. This allows utilisation of all kinds of networks
as users with bandwidth limitations may choose to play a subset of the
available streams (e.g. just audio that requires much less bandwidth than
video).
The player
schedules real-time packet transmission based on the timestamp in the index
entry. RTP compliant media provide
additional information in the RTP header that can be used for providing
smoother playback (see Section 10.2). Other media (e.g. shared workspace)
packets are sent on the network based on their received timestamp (i.e. with
the same inter-packet gap as they originally arrived).
The different
media characteristics affect the fast forward and rewind operations. Audio and
video are continuous media and therefore moving to a random point in the stream
simply involves skipping intermediate parts and restarting at the new position.
Additionally, the RTP header of the packets must be modified to maintain the
continuity in timestamps and sequence numbers. For non-continuous media, such
as shared workspace (wb/nte) fast-forward should involve the transmission of
intermediate parts so that the data set is complete.
The ACC Scalable Video
Distributed Architecture (SVDA) is another player/browser/recorder system,
which illustrates the mechanisms that can be provided for large video stores.
It is shown schematically in Fig.16.
This
system is designed to be able to process a significant number of simultaneous
requests from a large library of multimedia data. At the highest level of abstraction,
SVDA can be considered as consisting of three parts:
·
The main server, responsible for serving user requests and managing the
multimedia clips,
·
VFS (Video File Server) proxies, covering video servers,
·
AS (Archive Server) proxies, covering storage devices.
Figure 16 Architecture of SVDA
The
system functionality for playing, browsing or recording multimedia streams is
gathered together in one module, called the ‘main server’. It is the only part
of the system that is visible to a client, actually. The main server:
·
makes available
to a client a large storage space for saving video clips,
·
facilitates
browsing by establishing a file system with hierarchical directory structure,
·
provides access
control mechanisms such as ownership of multimedia data or access rights to it
and, finally,
·
allows the
delivery of the saved data to the specified destination point.
Other modules
mentioned above, i.e. the VFS and AS proxies, are relevant to another feature
of SVDA system — the ‘virtual file system’. This virtual file system’ property
distinguishes SVDA from other systems. The ‘virtual file system’ property means
that the system offers clients a transparent, consistent view of a large
storage space - possibly spread across many different file systems, without
almost their being aware of their existence. The system assumptions are that
the disk space of video servers is not sufficient to store all multimedia data,
and that only tertiary storage device is large enough to keep them all. Such
storage is not usually designed for real-time replay of real-time data. Thus
when a user wants to play a clip, he normally makes a reservation stating the
time at which the clip should be ready to play (i.e. copied onto a video server),
and the system will do everything possible to actually copy it there.
By introducing
new objects, the VFS and AS proxies, and employing CORBA technology [cor], the
system can be expanded easily by adding new video and archive servers. To
enlarge the system, a programmer has merely to implement a well-defined CORBA
interface. Provided another storage controller also supports CORBA, it is easy
to substitute one specialised mass storage device with another. Thus SVDA is
almost independent of hardware solutions. Moreover, in line with the CORBA
concept of component reusability, any CORBA-compliant system can simply take
advantage of proxies once they have been created. These considerations apply
only to the data flow control; nothing has been stated yet about the multimedia
data transport, and SVDA does not constrain the protocols that can be used for data
transmission.
The system uses
CORBA technology only for controlling data flow; it leaves multimedia data
transmission to the video server. Thus the way the data is sent over the
network depend only on capabilities of the video server used by the system. If
the server was able to provide data only with raw UDP datagrams, the system
would be limited to this protocol. But if the video server is able to send data
using RTP or multicast, the system seems to be more useful. The current
implementation that uses Sun MediaCenter server can take advantage of
multicast.
An
example of a user session and consecutive data flow is presented in Fig. 17.
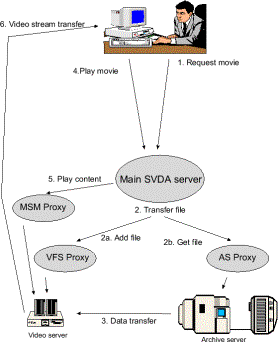
Figure 17 Example
of user session with SVDA
At
first sight, it seems that this system addresses a very different set of
applications from the rest of this section or indeed of this report. This is
not, however, the case. Although the system control is essentially unicast
client-server, so is SIP, H.323 etc., multicast is part of the data
distribution. The present implementation of the SVDA server is unicast, because
in real conferences media clips are always initiated by one person — so the client-server
model is appropriate.
There
are other detailed differences, but these are not architecturally significant.
The client-server control is via CORBA; this contrasts with the RTSP used for
this purpose in the relevant IETF protocols, but has similar, though less
targeted, functionality. The current browsing of the file structure and the
request for, and launching of, media clips is somewhat different from the
normal Mbone conference practice. But taking into consideration that SVDA is a
VoD tool rather than video conferencing one, such solution seems to be
suitable.
This document is
an attempt to gather together in one place the set of assumptions behind the
design of the Internet Multimedia Conferencing architecture, and the services
that are provided to support it. It discusses also the different aspects that
are being pursued in the MECCANO project.
The lightweight
session's model for Internet multimedia conferencing may not be appropriate for
all conferences, but for those sessions that do not require tightly-coupled
conference control, it provides an elegant style of conferencing that scales
from two participants to millions of participants. It achieves this scaling by virtue of the way that multicast
routing is receiver driven, keeping essential information about receivers local
to those receivers. Each new
participant only adds state close to him/her in the network. It also scales by not requiring explicit
conference join mechanisms; if everyone were to need to know exactly who is in
the session at any time, the scaling would be severely adversely affected. RTCP provides membership information that is
accurate when the group is small and increasingly only a statistical
representation of the membership as the group grows. Security is handled through the use of encryption rather than
through the control of data distribution.
For those that
require tightly coupled conferences, solutions such as H.323 are emerging.
There are still
many parts of this architecture that are incomplete, being still the subject of
active research. In particular,
differentiated services for
better-than-best-effort service show great promise to provide a more scalable
alternative to individual reservations. Multicast routing scales well to large
groups, but scales less well to large numbers of groups; we expect this will
become the subject of significant research over the next few years. Multicast
congestion control mechanisms are still a research topic, although in the last
year several schemes have emerged that show promise. Layered codecs show great
promise to allow conferences to scale in the face of heterogeneity, but the
join and leave mechanisms that allow them to perform receiver-based congestion
control are still being examined. We
have several working examples of reliable-multicast-based shared applications;
the next few years should see the start of standardisation work in this area as
appropriate multicast congestion control mechanisms emerge. Finally a complete security architecture for conferencing would be very desirable;
currently we have many parts of the solution, but are still waiting for an
appropriate key-distribution architecture to emerge from the security research
community. The approach described in this report is not a complete answer since it does not use the IPSEC technology
which most believe will be a key part of the future security infrastructure; it
is the best that can be deployed now in
the absence of large-scale IPSEC deployment.
The report also
gives some of the architectural considerations behind the gateways being
deployed, the networks supported and some of the other technologies provided.
The key feature of all of these is that they are capable of working in the
Internet multicast environment.
The Internet
Multimedia Conferencing architecture and the Mbone have come a long way from
their early beginnings on the DARTnet testbed in 1992. The picture is not yet finished, but it has
now taken shape sufficiently that we can see the form it will take. Whether or not the Internet does evolve into
the single communications network that is used for most telephone, television,
and other person-to-person communication, only time will tell. However, we believe that it is becoming
clear that if the industry decides that this should be the case, the Internet
should be up to the task.
Sections 2, 3,
4 and 6 of this Deliverable are based strongly on [han99-3], and the
contributions of Mark Handley and Jon Crowcroft are gratefully acknowledged. In
addition we acknowledge the many other members of the MECCANO project who have
contributed to the document in addition to those acknowledged as authors.
Finally, we acknowledge the very helpful comments from Peter Parnes, who acted
as peer reviewer; these comments caused significant improvements in the
deliverable.
[acoder] Papamichalis P E, “Practical Approaches to speech Coding”, Published by Prentice-Hall 1987
Gold B, “Digital
Speech Networks”, Proceedings of the IEEE,
Vol. 65, No. 12, December 1977.
Hardman, V et al., “Reliable Audio for Use over the
Internet”, in Proceedings of INET'95, June 1995, Honolulu, Hawaii.
[amir98] Amir, E et al., “An Active Service Framework and its Application to
Real-time Multimedia Transcoding”, ACM SIGCOMM’98, August 1998, Vancouver, Canada.
[asf] Advanced
Streaming Format (ASF) is a streaming multimedia file format developed by
Microsoft. http://www.microsoft.com/asf/
[avi] Audio
Video Interleave (AVI) is the file format for Microsoft’s Video for Windows standard.
[aw91] Feit, A-W, “XTV: A framework for
sharing X window clients in remote synchronous collaboration”, Proc. IEEE
TriComm (1991), pp 159-167.
[bach] Bacher, C & Müller, R:
“Generalised Replay of Multi-Streamed Authored Documents”, Proceedings of
ED-Media '98, Freiburg, June 1998
[bal98] Ballardie, A et al.,
“Core Based Tree (CBT) Multicast Border Router Specification”, Internet draft
<draft-idmr-cbt-br-spec-02.txt>, March 1998.
[begole] Begole, J, “Usability Problems and
Causes in Conventional Application-Sharing Systems”, http://simon.cs.vt.edu/~begolej/Papers/CTCritique/CTCritique.html http://simon.cs.vt.edu/~begolej/Papers/CTCritique/CTCritique.pdf
[bscw] GMD, “BSCW Shared Workspace
System”, http://bscw.gmd.de/
[cbq] Wakeman, I et al, “Implementing
Real Time Packet Forwarding Policies using Streams”, Usenix 1995 Technical
Conference, January 1995, New Orleans,
Louisiana, pp. 71-82.
[clark90] Clark, D &
Tennenhouse, D, “Architectural considerations for a new generation of
protocols”, in Proc. SIGCOMM’90, Philadelphia, September 1990.
[cor] Common Object Request Broker
Architecture (CORBA) http;//www.corba.org/
[crow98] Crowcroft, J et al: “RMFP: A Reliable
Multicast Framing Protocol”, Internet draft
<draft-crowcroft-rmfp-02.txt>, September 1998.
[deer88-1] Deering, S: “Multicast Routing in
Internetworks and Extended LANs”, ACM SIGCOMM 88, August 1988, pp 55-64 and
"Host Extensions for IP Multicasting", RFC 1112.
[deer88-2] Deering, S et al: “Distance Vector
Multicast Routing Protocol”, RFC 1075, Nov 1988.
[des] National Institute of Standards
and Technology (NIST), “FIPS Publication 46-1: Data Encryption Standard”,
January 22, 1988.
[difserv] Blake, S et al, “An architecture for
Differentiated Services”, RFC 2475, December 1998
Bernet, Y et al, “A Framework for Differentiated Services”,
Internet draft <draft-ietf-diffserv-framework-02.txt>, February, 1999.
[duros99] Duros, E et al, “A Link Layer
Tunnelling Mechanism for Unidirectional Links”, Internet draft
<draft-ietf-udlr-lltunnel-00.txt>, February 1999
[dvmrp]
DVMRP RFC 1075 Dense-mode Intra-domain Multicast routing
[estr99] Estrin, D et al., “The Multicast Address-Set
Claim (MASC) Protocol”, Internet draft <draft-ietf-malloc-masc-02.txt>,
July 1999.
[floy95] Floyd, S. et al., “A Reliable
Multicast Framework for Light-weight Sessions and Application Level Framing”, ACM SIGCOMM 1995, pp 342-356.
[froitz] Froitzheim, K et al., “CIO:JVTOS –
Joint Viewing and Teleoperation”,
http://www-vs.informatik.uni-ulm.de/projekte/JVTOS/CIO.html
[garf] Garfinkel, D et al., “HP SharedX:
A tool for real-time collaboration”, HP Journal, pp.
23-36
[gey98] Geyer, W & Effelsberg, W: “The
Digital Lecture Board - A Teaching and Learning Tool for Remote Instructions in
Higher Education”, In: Proc. of EDMEDIA'98, Freiburg, Germany, June 1998.
[ghan99] Ghanberi, M, “Video coding: an
introduction to standard codecs”, IEE
Telecommunications Series no. 42, Institute of
Electrical Engineering (IEE), UK, 1999.
[gup99] Gupta, V, “Secure,
Remote Access over the Internet using IPSec”, Internet draft <draft-gupta-ipsec-remote-access-02.txt>,
June 1999.
[h320] “Recommendation H.320: Narrow-band
visual telephone systems and terminal equipment”, ITU, Geneva, 1997.
[h323] “Recommendation H.323: Visual
telephone systems and equipment for local area networks which provide a non guaranteed quality of
service”, ITU, Geneva, 1996.
[h332] “Recommendation H.332: H.323
Extended for Loosely-Coupled conferences”, ITU, Geneva.
[han97] Handley, M & Crowcroft, J,
“Network Text Editor (NTE): A scalable shared text editor for the Mbone”,
Proceedings of ACM Sigcomm 97, Cannes, France, 1997.
[han98] Handley, M & Jacobson, V, “SDP:
Session Description Protocol”, RFC 2327, April 1998.
[han99-1] Handley, M et al., “SIP: Session
Initiation Protocol”, RFC 2543, March 1999.
[han99-2] Handley, M et al., “The Internet
Multicast Address Allocation Architecture”, Internet draft
<draft-ietf-malloc-arch-01.txt>, April 1999.
[han99-3] Handley, M et al., “The Internet
Multimedia Conferencing Architecture”, MMUSIC Working Group, Internet draft
<draft-ietf-mmusic-confarch-02>, May 1999.
[han99-4] Handley, M et al., “Session
Announcement Protocol”, Internet
draft <draft-ietf-mmusic-sap-v2-01.txt>, June 1999.
[hin96] Hinsch, E et al., “The
Secure Conferencing User Agent : A Tool to Provide Secure Conferencing with
MBONE Multimedia Conferencing Applications”, Proc. IDMS '96, Berlin, March
1996.
[icecar] Interworking Public Key
Certification Infrastructure for Commerce, Administration and Research,
http://ice-car.darmstadt.gmd.de/
[icesecarc] ICE-TEL Deliverable D1: “ICE-TEL
Certification Infrastructure Specification”,
http://www.darmstadt.gmd.de/ice-tel/
[ietf] Internet Engineering Task Force
(IETF), http://www.ietf.org/
[ipm] Deering, S, “Host
Extensions for IP Multicasting”, IETF RFC 1112, August 1989.
Fenner,
W, “Internet Group Management Protocol, Version 2”, IETF RFC 2236, updating RFC
1112, November 1997.
[iptv] Cisco IP/TV,
http://www.cisco.com/warp/public/732/net_enabled/iptv/index.shtml
[ipv6] Biemolt, W et al., “A
Guide to the Introduction of IPv6 in the IPv4 World”, Internet draft
<draft-ietf-ngtrans-introduction-to-ipv6-transition-01.txt>, June 1999.
[jacobson95] Jacobson, V,
“Multimedia conferencing on the Internet”, Tutorial slides, ACM SIGCOMM, August
1994.
[kirstein99] Kirstein, P T et al, “A Secure Multicast
Conferencing Architecture”, accepted for IDC’99, September 1999, Madrid.
[lai92] Lai, X, “On the design and
security of block ciphers”, ETH Series in Information Processing, J.L. Massey
(editor), Vol. 1, Hartung-Gorre Verlag Konstanz, Technische Hochschule
(Zurich), 1992.
[lam99] Lambrinos, L et al.,
“The Multicast Multimedia Conference Recorder”, in Proceedings of the Seventh
International Conference on Computer Communications and Networks, 12-15
October, Lafayette, Louisiana, USA.
[lbl] Lawrence
Berkeley Laboratories (LBL), Network Research Group
http://www-nrg.ee..lbl.gov/
[lien98] Lienhard, J & Maass, G, “AOFwb
- a new Alternative for the Mbone Whiteboard wb”, Proceedings of ED-Media '98,
Freiburg, June 1998
[linkworks] Digital, Compaq, “LinkWorks an
intelligent processor for mission-critical, document-based business processes”,
http://www.digital.com/info/linkworks/
[livegate] LIVE.COM, http://www.livegate.com/
[marra] MarraTech AB’s MarratechPro desktop
multimedia conferencing software (video, audio, slides, chat and whiteboard).
http://www.marratech.com/
[mash] The MASH research group at the
University of California, Berkeley
http://www-mash.cs.berkeley.edu/mash/
[mates] Multimedia Assisted distributed
Tele-Engineering Services (MATES), ESPRIT 20598 project, Information Technology
in the 4th Framework Program of the European Community.
http://www.cdt.luth.se/~mates/
[mau99] Mauve, M, “TeCo3D - A 3D
Telecooperation Application based on Java and VRML”. In Proc. of MMCN/SPIE'99,
pp. 240-251, San Jose, USA, January 1999.
[mcca95] McCanne, S & Vetterli, M, “Joint
Source/Channel Coding for Multicast
Packet Video”. Proceedings of the IEEE International Conference on Image
Processing. October, 1995. Washington, DC.
[mcca96] McCanne, S et al., “Receiver-driven
Layered Multicast”. ACM SIGCOMM, August 1996, Stanford, CA, pp. 117-130.
[merci] Multimedia
European Research Conferencing Integration (MERCI)
http://www-mice.cs.ucl.ac.uk/multimedia/projects/merci/
[mice] Multimedia
Integrated Conferencing for Europe (MICE)
http://www-mice.cs.ucl.ac.uk/multimedia/projects/merci/
[mpeg] Moving Pictures Experts Group
(MPEG), officially ISO/IEC JTC1 SC29 WG11. See http://drogo.cselt.it/mpeg/
[mpoll] Patrick, A, “User-Centred an Mbone
Videoconference Polling Tool”, March 11, 1998.
http://debra.dgbt.doc.ca/mbone/mpoll/development/
MPoll application at
http://www.merci.crc.doc.ca/mbone/mpoll/
[netm] Microsoft Corporation,
“NetMeeting”, http://www.microsoft.com/windows/netmeeting/
[nshow] Windows NT
Server NetShow Services
http://www.microsoft.com/Windows/windowsmedia/technologies/servers.htm
NetShow
player with Internet Explorer, Windows 95, and Windows NT
http://www.microsoft.com/Windows/windowsmedia/technologies/player2.htm
[ott] Ott, J et al, “A Message Bus for
Conferencing Systems”, Internet draft
<draft-ietf-mmusic-mbus-transport-00.txt>, November 1998.
Ott, J et al, “The Message Bus: Messages and Procedures”, Internet
draft <draft-ott-mmusic-mbus-semantics-00.txt>, June 1999.
Ott, J et al, “Requirements for Local Conference Control”,
Internet draft <draft-ott-mmusic-mbus-req-00.txt>, June 1999
[ovs]
Oracle Video Server,
http://www.oracle.com/itv/ovs.html
[patel99] Patel, BV et al., “Multicast
Address Allocation Configuration Options”, Internet draft
<draft-ietf-dhc-multopt-03.txt>, February 1999.
[pgp]
Atkins, D et al., “PGP
Message Exchange Formats”, Internet RFC 1991, August 1996.
[phil98] Phillips, G & Smirnov, M, “Address
utilisation in the MASC/BGMP architecture”, Internet draft
<draft-phillips-malloc-util-00.txt>, July 1998.
[pimdm] Deering, S et al., “Protocol Independent Multicast
Version 2 Dense Mode Specification”, Internet draft
<draft-ietf-pim-v2-dm-03.txt>, June 1999.
[pimsm] Estrin, D et al., “Protocol
Independent Multicast-Sparse Mode (PIM-SM): Protocol Specification”, Internet
RFC 2362, June 1998.
[rasmus] Rasmusson,
L, “About the data format of wb”, 14 December 1995.
http://www.it.kth.se/~d90-lra/wb-proto.html
[realn] RealNetworks, http://www.real.com/
[redenc] Perkins, C et al., “RTP Payload for
Redundant Audio Data”, IETF RFC 2198, September 1997
[riv92] Rivest, R, “The MD5 Message-Digest
Algorithm”, RFC 1321, MIT Laboratory
for Computer Science and RSA Data Security, Inc., April 1992.
[rosen98] Rosenberg, J & Schulzrinne, H, “An
RTP Payload Format for Generic Forward Error Correction”, IETF Internet Draft,
Nov. 1998.
[rozek96] Rozek, A, “TeleDraw – a
platform-independent shared whiteboard”, 1996.
http://www.uni-stuttgart.de/Rus/Projekte/MERCI/MERCI/TeleDraw/Info.html
[rmrg] IRTF Research Group on Reliable
Multicast, http://www.east.isi.edu/RMRG/.
[rs] Rosenberg, J &
Schulzrinne, H, “An RTP Payload Format for Reed Solomon Codes”, IETF Internet
Draft, Nov. 1998.
[rsvp] Braden, R, Editor, “Resource
ReSerVation Protocol (RSVP) -- Version 1 Functional Specification”, IETF RFC
2205, September 1997.
[rsvp-cls] Wroclawski, J, “Specification of
the Controlled-Load Network Element Service”, IETF RFC 2211, September 1997.
[rsvp-gs] Shenker, S et al., “Specification
of Guaranteed Quality of Service”, IETF RFC 2212, September 1997.
[rtpf] Payload Formats RFC 2032, 2035, etc. for specific codecs.
[rtptrans] Sisalem, D & Casner,
S, “RTP translator between unicast and multicast networks; also translates
between VAT and RTP formats”,
http://www.cs.columbia.edu/~hgs/rtptools/#rtptrans
[rtsp] H. Schulzrinne, H et
al., “Real Time Streaming Protocol (RTSP)”, IETF RFC 2326, April 1998.
[sahouria] Sahouria, E, “Bibliography for Content
Based Video”, personal web page http://www-video.eecs.berkeley.edu/~emile/bib.html
[scalvico] Horn, U et al., “Robust Internet Video
Transmission Based on Scalable Coding and Unequal Error Protection”, in Image
Communication, Special Issue on Real-Time Video over the Internet, accepted for
publication, 1999.
[schu96-1] Schulzrinne, H et al., “RTP: A
Transport Protocol for Real-Time Applications”, IETF RFC 1889, January 1996.
[schu96-2] Schulzrinne, H, “RTP Profile for
Audio and Video Conferences with Minimal Control”, IETF RFC 1890, January 1996.
[sdr] Session
Directory (SDR),
http://www-mice.cs.ucl.ac.uk/multimedia/software/sdr/.
[sunf] Sun Microsystems, “SunForum 2.0
Workgroup Collaboration Tools”,
http://www.sun.com/desktop/products/software/sunforum/
[t120] ITU
Recommendation T.120, February 1996
[tdes] American National Standards
Institute, “Triple Data Encryption Algorithm Modes of Operation,” ANSI
X9.52-1998, 1998.
[tennen96] Tennenhouse,
D & Wetherall, D, “Towards an Active Network Architecture”, Computer
Communication Review, Vol. 26, No. 2, April 1996.
See also
http://www.sds.lcs.mit.edu/activeware/
[thal98] Thaler, D et al.,
“Border Gateway Multicast Protocol (BGMP):Protocol Specification”, Internet
draft <draft-ietf-idmr-gum-04.txt>, November 1998.
[udlr] UniDirectional Link Routing home
page, http://www-sop.inria.fr/rodeo/udlr/
[vcoder] Furht, B, et al., “Motion Estimation
Algorithms for Video Compression”,
ISBN 0-7923-9793-2, Kluwer Academic Publishers, 1997.
Sullivan, GJ &
Wiegand, T, “Rate-Distortion Optimization for Video Compression”, in IEEE Signal Processing Magazine, November
1998.
Bhaskaran, V &
Konstantinides, K, “Image and Video Compression Standards: Algorithms and
Architectures” ISBN 0-7923-9591-3, Kluwer Academic Publishers, 1995.
Ghanberi, M, “Video
coding: an introduction to standard codecs”, IEE Telecommunications Series no. 42, the
Institute of Electrical Engineering (IEE), UK, 1999.
[vnc] AT&T Laboratories,
Cambridge, “Virtual Network Computing (VNC)”,
http://www.uk.research.att.com/vnc/
[wolf] Wolf, H et
al., “MaX (formerly QuiX) – Macintosh Quickdraw to X Window Converter”,
http://www-vs.informatik.uni-ulm.de/projekte/JVTOS/QuickXKonv.html
[x509] CCITT (Consultative Committee on
International Telegraphy and
Telephony). “Recommendation X.509: The Directory - Authentication Framework”, 1988.